NCBI Datasets是一种新的资源,可以让您轻松地从跨NCBI数据库收集数据。您可以使用它来查找和下载基因和基因组的序列、注释和元数据,使用我们的命令行界面(CLI)工具或NCBI Datasets web界面。
下载并安装
下载的链接在这里,根据自己的电脑版本找到相应的安装包
https://www.ncbi.nlm.nih.gov/datasets/docs/v2/download-and-install/
展示linux系统安装的流程:
1、通过curl安装
下载 datasets: curl -o datasets ‘https://ftp.ncbi.nlm.nih.gov/pub/datasets/command-line/v1/linux-amd64/datasets‘
下载 dataformat: curl -o dataformat ‘https://ftp.ncbi.nlm.nih.gov/pub/datasets/command-line/v1/linux-amd64/dataformat‘
修改一下权限:chmod +x datasets dataformat
未修改权限前是一个不能执行的文件(这里我用绿色来区分可以执行的命令,即在交互式页面可以直接键入使用,例如linux自带的“ls”命令一样)

修改权限后:

datasets -h #测试你是否安装成功
2、通过conda 进行安装
首先创建一个conda环境: conda create -n ncbi_datasets
然后激活这个环境: conda activate ncbi_datasets
最后通过这条命令进行安装: conda install -c conda-forge ncbi-datasets-cli”<14″
用法
通过上述的下载,小花相信你已经下载了好了datasets,下面来看看datasets怎么用叭~
网页粘贴代码
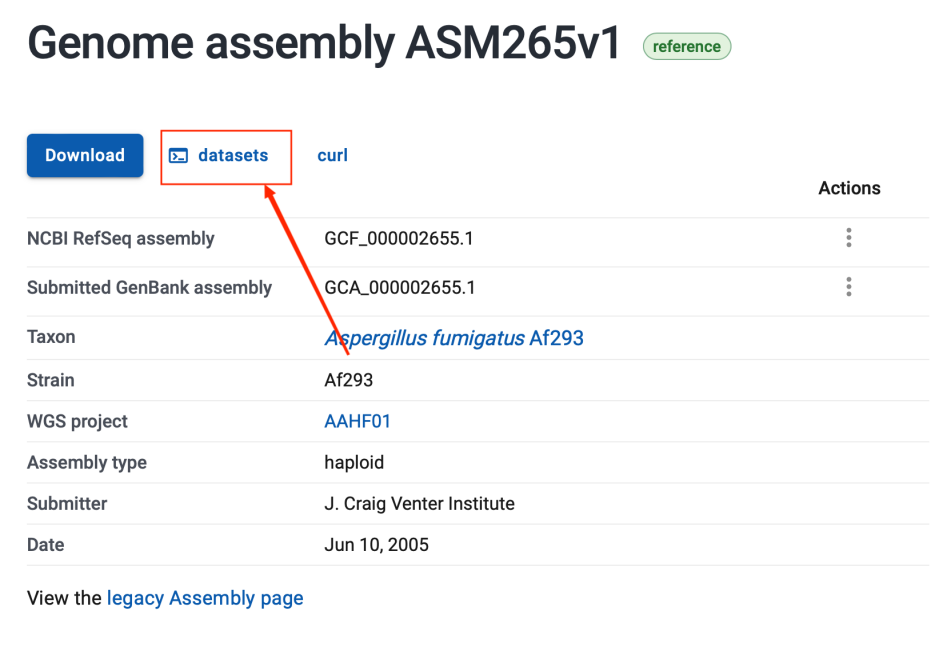
我们可以从网上看到相关的下载代码,复制下来在命令行输入相关代码。
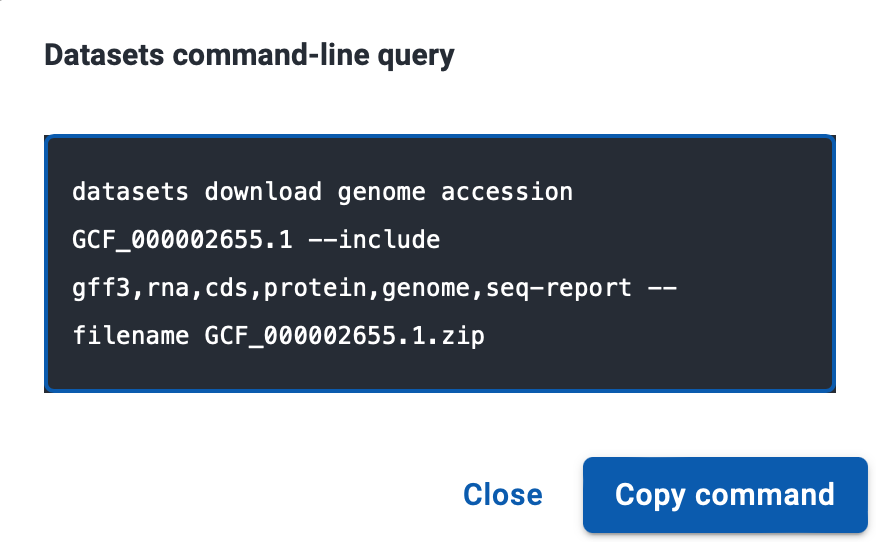
复制这段代码:
datasets download genome accession GCF_000002655.1 –include gff3,rna,cds,protein,genome,seq-report –filename GCF_000002655.1.zip
这种方法给小白带来的福利哦~

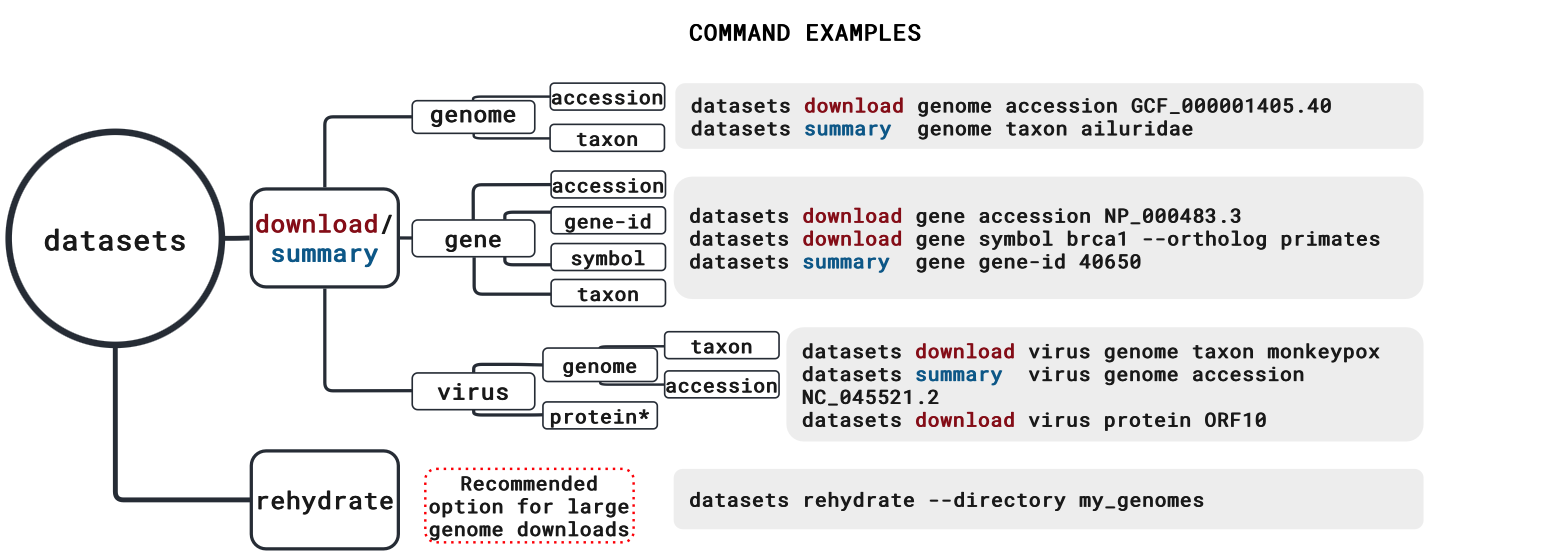
在讲用法之前我们先对照上图了解这个小软件的所有用法。
基因组的下载
#单独下载某一个基因组信息
datasets download genome accession GCF_000001405.40
#下载某一个物种下的所有的基因组信息
datasets download genome taxon “Candida lusitaniae”
#下载人类的基因组信息
datasets download genome taxon “human” –filename human_dataset.zip
datasets download genome accession GCF_000001405.40 –filename human_GRCh38_dataset.zip
下载的过程中会显示: 
下载完成后的信息会显示:
![]()
除此之外,以BioProject 方式下载
datasets download genome accession PRJEB33226 –filename sanger_bioproject_dataset.zip
下面小花列出常用命令,读者可以根据自己的需求进行选择
#下载人类参考基因组
datasets download genome taxon human –reference
![]()
#获取注释人类基因组的数据
datasets download genome taxon human –annotated
![]()
#以“完整基因组”的装配水平获取人类基因组数据
datasets download genome taxon human –assembly-level complete

#获取2020年1月1日之后发布的人类基因组数据
datasets download genome taxon human –released-after 01/01/2020

#获取T2T联盟提交的人类基因组数据
datasets download genome taxon human –search ‘T2T Consortium’

基因的下载
除了基因组的下载,基因的下载也是可以解决的。
#基因的下载
datasets gene accession
datasets gene gene-id
通过提供单个或多个基因id(空格分隔)下载基因数据包。如果使用——inputfile选项,每个gene-id应该在单独的一行中。
datasets download gene gene-id 1 2 3 9 10 11 12 13 14 15 16 17

执行如下命令,按基因符号下载基因数据包。
datasets download gene symbol ACRV1 A2M –taxon human

通过RefSeq核苷酸或蛋白质加入下载基因数据包。
datasets download gene accession NM_020107.5 NP_001334352.2

按物种名称或分类号下载基因资料包。运行以下命令下载所有人类基因的基因数据包。
datasets download gene taxon human

真核基因数据包默认包含转录物、蛋白质序列和元数据,而原核数据包含基因和蛋白质序列,外加元数据。可以选择添加额外的数据文件,或者只在数据包中包含元数据,使用——include一个或多个术语。下面是一些使用——include标志来选择在数据包中包含哪些数据文件的示例。
获取人类BRCA1基因(gene-id: 672)的基因和蛋白质序列:
datasets download gene gene-id 672 –include gene,protein

这个示例中获取了gene-id为672的基因序列ncbi_dataset/data/gene.fna和蛋白质序列ncbi_dataset/data/protein.faa
获取人类BRCA1基因(gene-id: 672)的基因、转录本、CDS和蛋白质序列:
datasets download gene gene-id 672 –include gene,rna,cds,protein
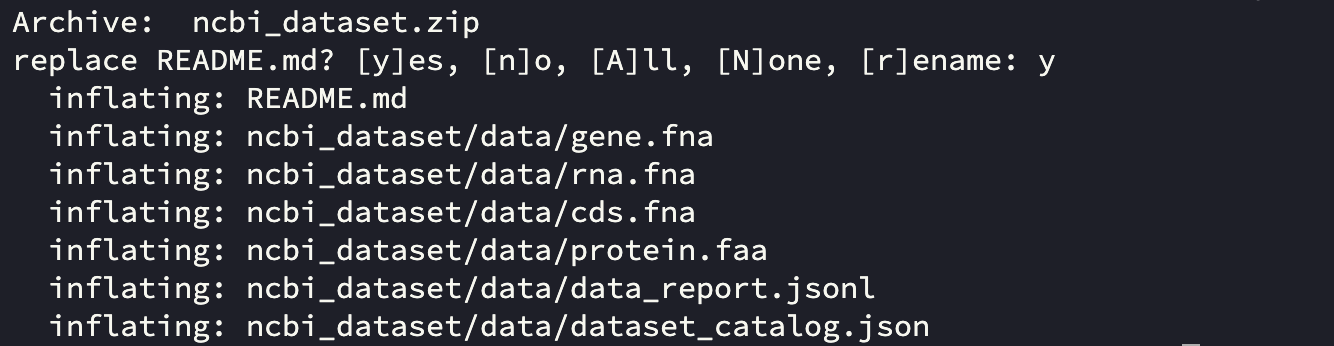
这个示例中,
获取一个只有基因数据报告(元数据)的数据包:
datasets download gene gene-id 672 –include none
庞大的基因组的下载方法
#大基因组的下载
1、下载的命令datasets download genome taxon “human” –dehydrated
下载显示:

2、解压unzip ncbi_dataset.zip
这样下载ncbi_dataset.zip解压后,你会看到如下的

在压缩包中文件中fetch.txt存储了下载的信息
3、nohup datasets rehydrate –directory ./
运行上述的命令才开始下载相关的基因组的信息。这里的命令挂在了后台,如果中断可以再次提交,会从中断的地方再下载的。这一点对于下载庞大的基因组来讲是非常的有利的。
这里小花强烈建议超过100个基因组以上采用上述的办法,进行下载。
如果遇到不懂的也可以借助线上的云平台哦~http://www.biocloudservice.com/home.html
好了今天的序列下载工具就讲到这里,欢迎大家有问题与小花一起讨论哦~