小伙伴在做生信分析的时候,会经常见到聚类这个名词,却不知道是什么意义。其实平时我们做基因热图时候就用到了聚类的思想。有的小伙伴在做癌症分析时候,也见过给疾病做分子亚型,这个时候无监督聚类就派上用场了。
所以今天小果带大家了解无监督聚类,并学习如何使用他。
首先我们先大致了解一下什么是无监督聚类。就好比一致性聚类方法包括从一组项目中进行次抽样,例如微阵列,并确定特定簇计数(k)的簇。然后,对共识值,两个项目占在同一子样本中发生的次数中有相同的聚类,计算并存储在每个k的对称一致矩阵中。
具体的含义我们不在此一一赘述。
小果在这里用到的是ConsensusClusterPlus这个包对基因进行聚类。
所需要的是下面这种格式的基因表达谱:

#install.packages(“BiocManager”)
#BiocManager::install(‘ConsensusClusterPlus’)#小伙伴没有的自己要下载一下
library(tidyverse)
library(ConsensusClusterPlus)
#导入数据
exp <- read.table(“text1.txt”,sep = “\t”,row.names = 1,check.names = F,stringsAsFactors = F,header = T)
d=as.matrix(exp)
gene <- c(“MMP9″,”CCND1″,”STAT1″,”AR”,”AKR1C3″,”GSTP1″,”PGR”)
d <- d[gene,]
mads=apply(d,1,mad)
d=d[rev(order(mads))[1:7],] #7是基因个数
d = sweep(d,1, apply(d,1,median,na.rm=T))
title=(“JULEI”) ##文件夹输出图片的位置
set.seed(1) #我发现设不设置种子都一样
#这里小果选取自己的示例数据,小伙伴们整理自己想去聚类的基因。
然后我们打开JULEI这个文件夹会发现得到了聚类的结果:
 一致性矩阵
一致性矩阵
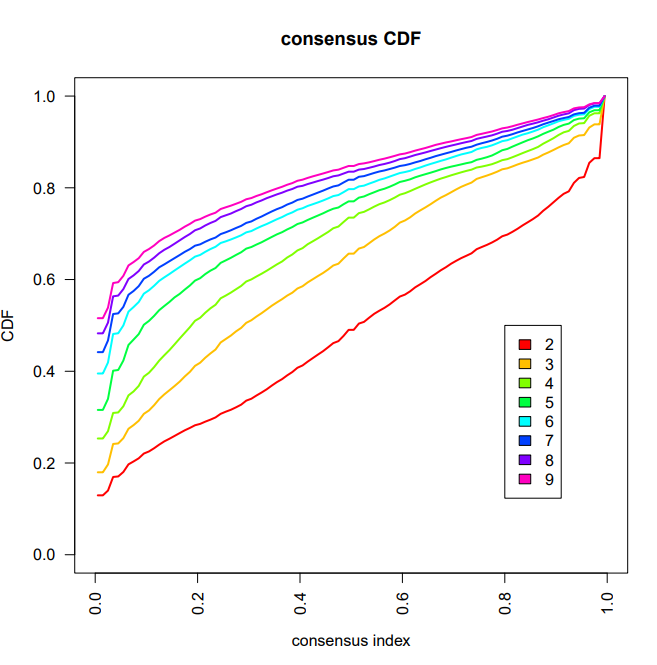
 一致性累积分布函数图
一致性累积分布函数图
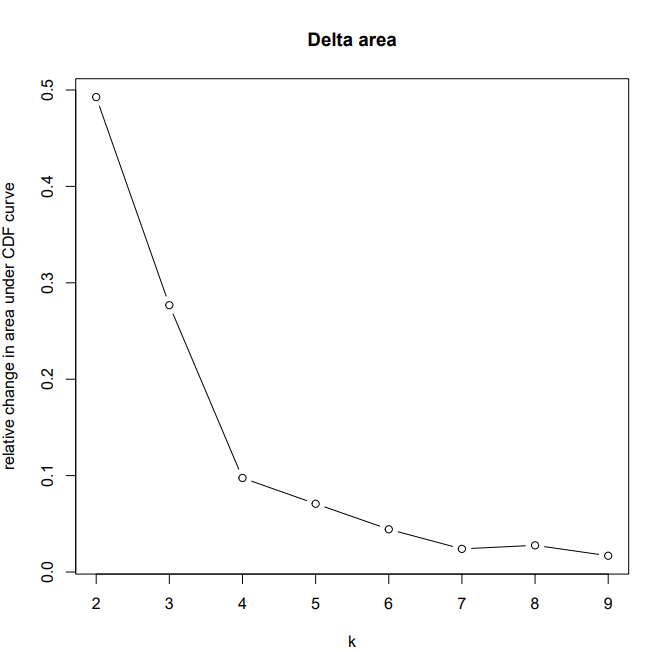
 碎石图
碎石图
在这里小果就不全部展示了,小伙伴们自己做的话可以慢慢看。
从上述碎石图看出呢,在k=7,k=8左右时候呢,比较平稳,前面K=3,和k=4这两个分组数间相对差值变化越大,说明该分组越有价值。小伙伴需要对症下药,查看自己聚类的结果进行解释和后续的分析。
图中K值呢就代表簇,
接下来我们绘制另一组图:
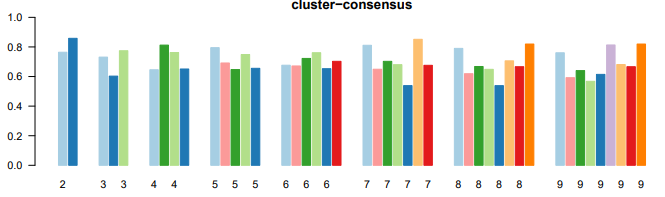
聚类一致性(cluster-consensus)以及样品一致性(item-consensus)
title=title,clusterAlg=”hc”,distance=”pearson”,seed=1,plot=”pdf”)
results[[2]][[“consensusMatrix”]][1:5,1:5]
results[[2]][[“consensusTree”]]
results[[2]][[“consensusClass”]][1:5]
icl = calcICL(results,title=title,plot=”pdf”) ##画另一组图片
结果如下:
聚类一致性(cluster-consensus)
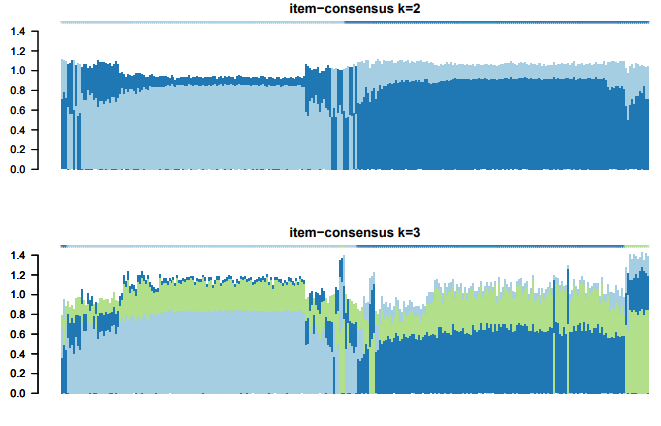
样品一致性(item-consensus)
小伙伴们把需要那些图片进行展示就可以了。
#上述就是绘制另一组图,然而我们还需要做的是把结果保存下来。
group<-results[[2]][[“consensusClass”]]
group<-as.data.frame(group)
group$group <- factor(group$group,levels=c(1,2))
save(group,file = “group_AY.Rda”)#这里把分组结果保存
然而,又会有小伙伴会问如何展示聚类后的效果呢。
小果在这里教大家一种方式用热图的方式进展展示,
绘制ConsensusClusterPlus后的热图:
这个时候就用到上述咱们保存的分组信息了:
跟着小果的代码往下跑就可以啦!
library(pheatmap)#调用一下热图的包
group <- group %>%
rownames_to_column(“sample”)
annotation <- group %>% arrange(group) %>% column_to_rownames(“sample”)
a <- group %>% arrange(group) %>% mutate(sample=substring(.$sample,1,12))
b <- t(exp_gene) %>%
as.data.frame() %>%
rownames_to_column(“sample”) %>%
mutate(sample=substring(.$sample,1,12))
c <- inner_join(a,b,”sample”) %>% .[,-2] %>% column_to_rownames(“sample”) %>% t(.)
pheatmap(c,annotation = annotation,
cluster_cols = F,fontsize=5,fontsize_row=5,
scale=”row”,show_colnames=F,
fontsize_col=3)
bk <- c(seq(-5,-0.1,by=0.01),seq(0,5,by=0.01))
pheatmap(c,annotation = annotation,
annotation_colors = list(group = c(“1″ =”#8B1C62”,”2″= “#EE9572″)),
cluster_cols = F,fontsize=10,fontsize_row=10,
scale=”row”,show_colnames=F,cluster_row = F,
color = c(colorRampPalette(colors = c(“#551A8B”,”white”))(length(bk)/2),colorRampPalette(colors = c(“white”,”#CD3700″))(length(bk)/2)),
#legend_breaks=seq(-3,3,1),
fontsize_col=3)
dev.off()
这里热图的参数比如:颜色的绘制都可以根据小伙伴自己的需求来修改,
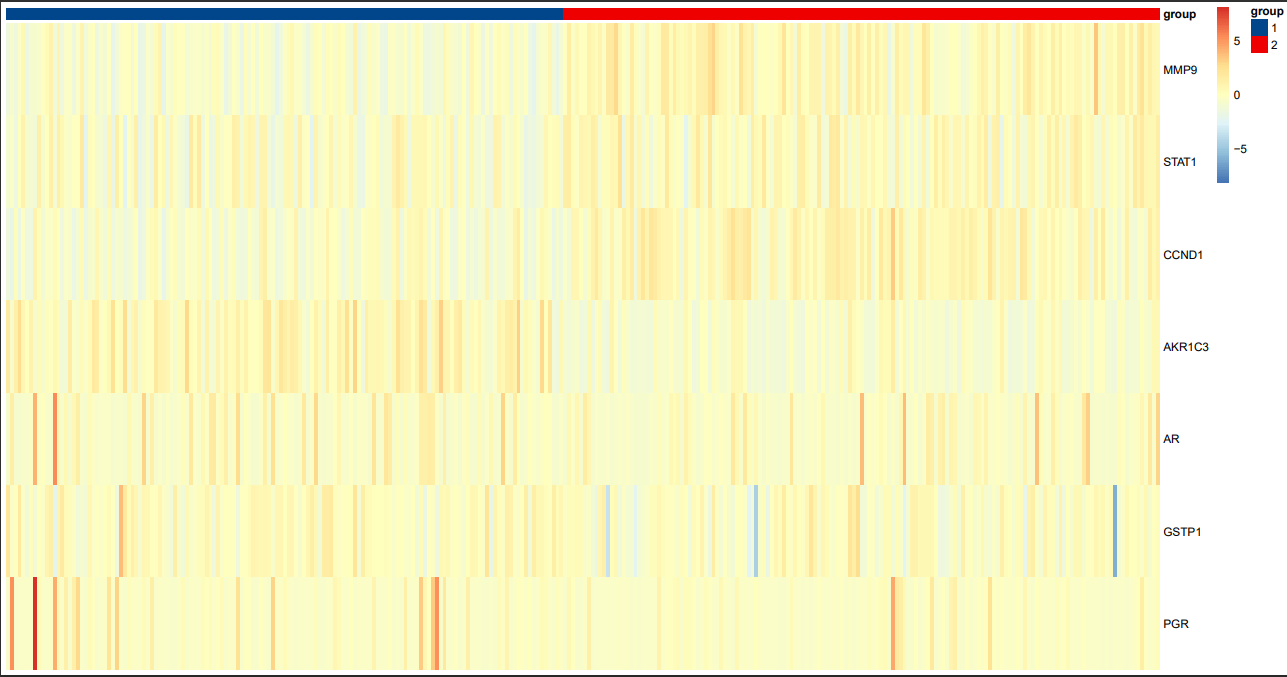
效果就出来了,可以看出来在MMP9和CCND1等这几个基因聚类效果比较明显,小果在这里展示的是K=2情况下聚类的热图。小伙伴们自己选择K的值进行绘制。
下面就可以根据聚类的结果去后续的分析了。比如;分组的ssGSEA等等
小伙伴们需要多多学习代码的含义,以及对图片的理解才能,更好的去运用。
上述就是对无监督聚类法的学习。小伙伴们是否学会了呢