R语言是一种广泛应用于数据分析和统计建模的编程语言,其生态系统拥有丰富的扩展包(packages),以满足各种数据处理和可视化的需求。“proxy”语言包意味着该包的核心目标是处理数据对象之间的相似度或距离。在数据分析和机器学习领域,度量数据对象之间的距离或相似度是一个常见而重要的任务。“proxy”包提供了多种计算对象相似性的方法,帮助数据科学家和研究人员更好地理解和处理数据。
该包的主要特点之一是其高度的灵活性。“proxy”包为用户提供了丰富的距离计算方法和相似性度量指标,涵盖了多种数据类型和应用场景。用户可以根据自己的研究需求和数据特点,选择合适的距离度量方法。
要使用proxy包,可以在R中使用以下命令进行安装和加载:
> install.packages(“proxy”) #安装proxy语言包
> library(proxy) #加载语言包
在处理大规模数据时,计算距离和相似性可能成为性能瓶颈。“proxy”包通过优化算法和并行计算,提供了高效的数据处理能力,能够在较短的时间内处理大量数据对象。
示例:
我们安装并加载了”proxy”包,并使用一个简化的基因表达矩阵作为示例数据。基因表达矩阵是一个6行2列的矩阵,其中行表示基因,列表示样本,元素表示基因在不同样本中的表达值。
# 安装和加载所需的包
> install.packages(“proxy”)
> library(proxy)
# 示例数据:假设我们有一个基因表达矩阵,其中行表示基因,列表示样本
> gene_expression <- matrix(c(1.2, 2.3, 0.8, 4.1, 3.0, 2.5,
+ 0.9, 3.2, 1.5, 2.9, 3.5, 1.7), nrow = 6, ncol = 2)
接下来,我们使用proxy::dist()函数来计算距离矩阵。该函数接受一个数据矩阵作为输入,并返回一个表示数据对象之间距离的dist对象。在这个例子中,我们计算了基因表达矩阵中样本之间的欧氏距离。
# 创建数据对象(dist对象)用于计算距离和相似性
> data_dist <- proxy::dist(gene_expression)
# 查看计算出的距离矩阵
> print(data_dist)
1 2 3 4 5
2 2.5495098
3 0.7211103 2.2671568
4 3.5227830 1.8248288 3.5846897
5 3.1622777 0.7615773 2.9732137 1.2529964
6 1.5264338 1.5132746 1.7117243 2.0000000 1.8681542
进一步使用这些距离信息进行聚类分析、样本相似性聚类、多维缩放(MDS)等任务,这些任务通常在生物学研究中具有重要意义。
# 层次聚类
> hc <- hclust(data_dist)
> plot(hc)
#K均值聚类
> kmeans_result <- kmeans(gene_expression, centers = 3)
> cluster_labels <- kmeans_result$cluster
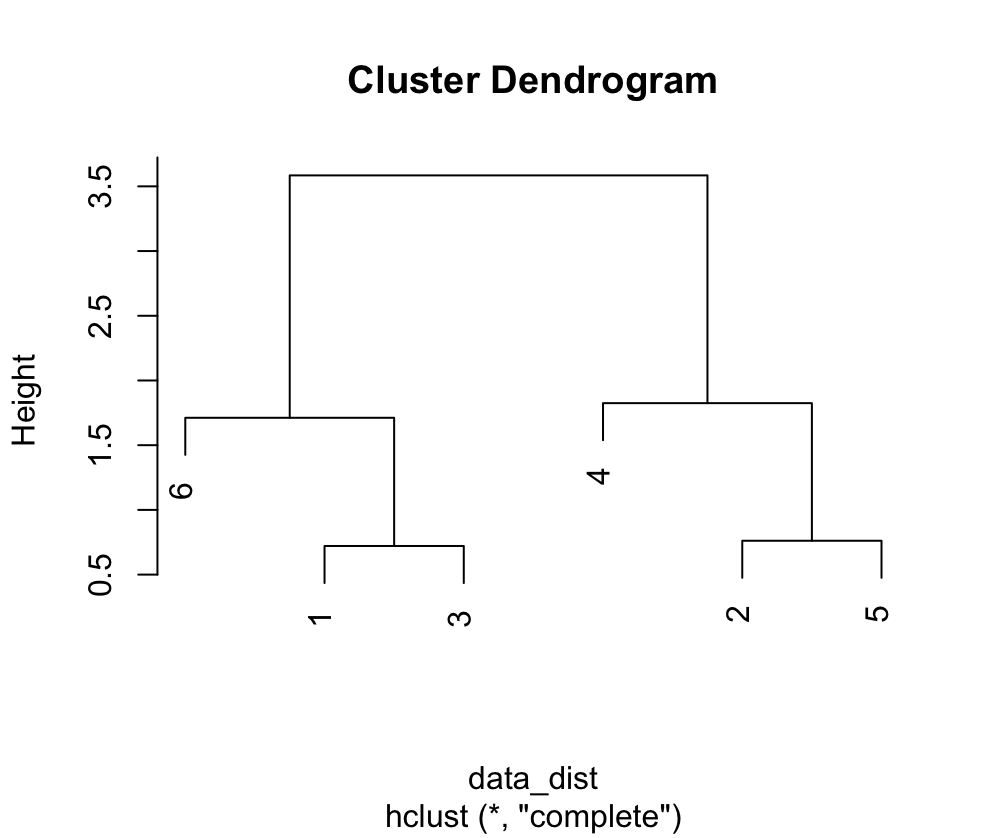
样本相似性聚类是将样本按照其相似性进行分组的过程。可以使用聚类算法将样本分成相似的群组,并进一步分析每个群组的特征。
# 样本相似性聚类
> sample_hc <- hclust(t(data_dist)) # 使用转置的距离矩阵进行样本聚类
> plot(sample_hc)

多维缩放(MDS)是一种将高维数据映射到低维空间以保持样本之间的距离信息的技术。通过MDS,我们可以将高维数据可视化为二维或三维图形,更好地理解数据之间的相似性和差异性。
# 多维缩放
> mds_result <- cmdscale(data_dist, k = 2) # 将距离矩阵映射到2维空间
> plot(mds_result, type = “n”)
> text(mds_result, labels = rownames(gene_expression))
此外,“proxy”包还与R生态系统中的其他包紧密集成,为用户提供全面的数据分析解决方案。无论是数据预处理、聚类分析还是分类任务,“proxy”包都能与其他常用包无缝衔接,使得用户在进行复杂的数据分析工作时得心应手。这种集成性为R用户提供了更加高效和便捷的工作流程,促进了数据科学和统计建模领域的发展。
以上就是对R语言包“proxy”的简单介绍啦,它为R用户提供了丰富的距离计算方法和相似性度量指标,帮助用户处理多种数据类型和规模的数据。“proxy”包的诞生填补了R语言在数据对象距离计算方面的空白,为数据科学家和研究人员提供了一个强大的数据分析工具。随着数据科学领域的不断发展,“proxy”包必将在数据分析和机器学习的研究中继续发挥重要作用,为用户带来更多的便利和可能性。
小伙伴们,今天有没有学到新知识呢,想要继续了解R语言内容可以持续关注小果哦~~或者也可以关注我们的官网也会持续更新的哦~ http://www.biocloudservice.com/home.html
References: