大家好,小果回来啦!
最近,小果深入研究了热图(Heatmap),它是数据可视化领域的一颗璀璨明星。它能够以直观、生动的方式展示数据之间的关系和模式,可以帮助我们在数据的海洋中寻找线索。
在我们深入探讨如何使用Seaborn库来绘制热图以及为什么选择Seaborn之前,让我们先来了解一下热图的基本概念,以及它在数据分析中的不可或缺之处。这个旅程将带领我们进入数据的神奇世界,一起来探索吧!
热图的基本概念
热图的核心思想是将数据集中的数值用色彩表示,从而形成一个矩阵图。通常,热图将两个维度的数据以矩阵的形式展示,其中一个维度代表数据的行,另一个代表列。每个单元格的颜色根据数据值的大小而变化,从而直观地呈现了数据的模式、关联和差异。
为什么使用热图?
数据关系可视化:热图能够帮助我们迅速发现数据中的相关性和趋势。例如,在生物学领域,可以使用基因表达数据制作热图,以观察哪些基因在不同条件下表现出相似的模式,从而识别潜在的生物学关系
数据降维:热图有助于将大量数据压缩成可管理的图形,而不会丢失重要信息。这对于大规模数据集的快速可视化和理解非常有用。
趋势分析:热图可以帮助您识别数据中的趋势和异常。通过观察颜色的变化,您可以识别出数据中的高点、低点和异常值。
数据聚类:热图常用于聚类分析,将相似的数据项分组在一起。这有助于理解数据的结构并发现潜在的群组。
为什么选择Seaborn来绘制热图?
Seaborn是一个基于Matplotlib的Python数据可视化库,为什么我们更愿意选择Seaborn来绘制热图,而不是使用Matplotlib或R呢?以下是Seaborn在热图绘制中的一些优点:
美观性:Seaborn以美观的默认样式著称,因此您可以轻松创建具有吸引力的热图,无需太多自定义。
简化API:相对于Matplotlib,Seaborn提供了更简单的API来创建热图。您可以使用一行代码创建一个热图,而无需编写大量的绘图代码。
统计数据可视化:Seaborn专注于统计数据可视化,因此它提供了一些高级功能,如对数据进行分组、绘制不同子集的热图等。
内置颜色映射:Seaborn提供了多种内置的颜色映射,使您可以轻松选择适合数据的颜色,而不必自己定义。
与Pandas集成:Seaborn与Pandas非常兼容,可以直接使用数据框创建热图,不需要额外的数据处理步骤。
活跃的社区支持:Seaborn有一个活跃的社区,提供了大量示例和文档,使学习和使用变得更加容易。
下面让我们使用Seaborn进行示范,代码如下:
import seaborn as sns
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 创建一个包含10行10列随机数的数据框,列名为a到j
df = pd.DataFrame(np.random.random((10, 10)), columns=[“a”, “b”, “c”, “d”, “e”, “f”, “g”, “h”, “i”, “j”])
# 绘制一个热力图,cbar参数表示不显示颜色条
sns.heatmap(df, cbar=False)
plt.show()
# 绘制一个热力图,使用蓝色调色板(cmap=”Blues”)
sns.heatmap(df, cmap=”Blues”)
plt.show()
# 绘制一个热力图,显示每个单元格的数值,设置注释文本字体大小为7
sns.heatmap(df, annot=True, annot_kws={“size”: 7})
plt.show()
# 绘制一个热力图,增加单元格之间的线宽为2,线的颜色为黄色
sns.heatmap(df, linewidths=2, linecolor=’yellow’)
plt.show()  修改色调为蓝色:
修改色调为蓝色:  为每个单元格填充数值:
为每个单元格填充数值:  使用自定义网格线绘制热图:
使用自定义网格线绘制热图:  当然也可以绘制好看的聚类热图,示例代码如下所示:
当然也可以绘制好看的聚类热图,示例代码如下所示:
import seaborn as sns
import pandas as pd
from matplotlib import pyplot as plt
# 导入数据集
url = ‘https://raw.githubusercontent.com/holtzy/The-Python-Graph-Gallery/master/static/data/mtcars.csv’
# 从给定URL读取CSV文件并创建一个数据框
df = pd.read_csv(url)
# 将’model’列设置为数据框的索引,作为行标签
df = df.set_index(‘model’)
# 准备一个颜色向量,根据’cyl’列的值映射颜色
my_palette = dict(zip(df.cyl.unique(), [“orange”, “yellow”, “brown”]))
# 创建一个字典,将唯一的’cyl’值与颜色相对应,然后通过’map’方法将颜色映射到每行
row_colors = df.cyl.map(my_palette)
# 绘制簇状图
sns.clustermap(df, metric=”correlation”, method=”single”, cmap=”Blues”, standard_scale=1, row_colors=row_colors)
# 使用Seaborn的clustermap函数绘制聚类热图,使用”correlation”作为相似性度量,”single”作为聚类方法,”Blues”作为颜色映射,
# “standard_scale=1″用于标准化数据,row_colors参数将之前创建的颜色向量应用于行
plt.show()
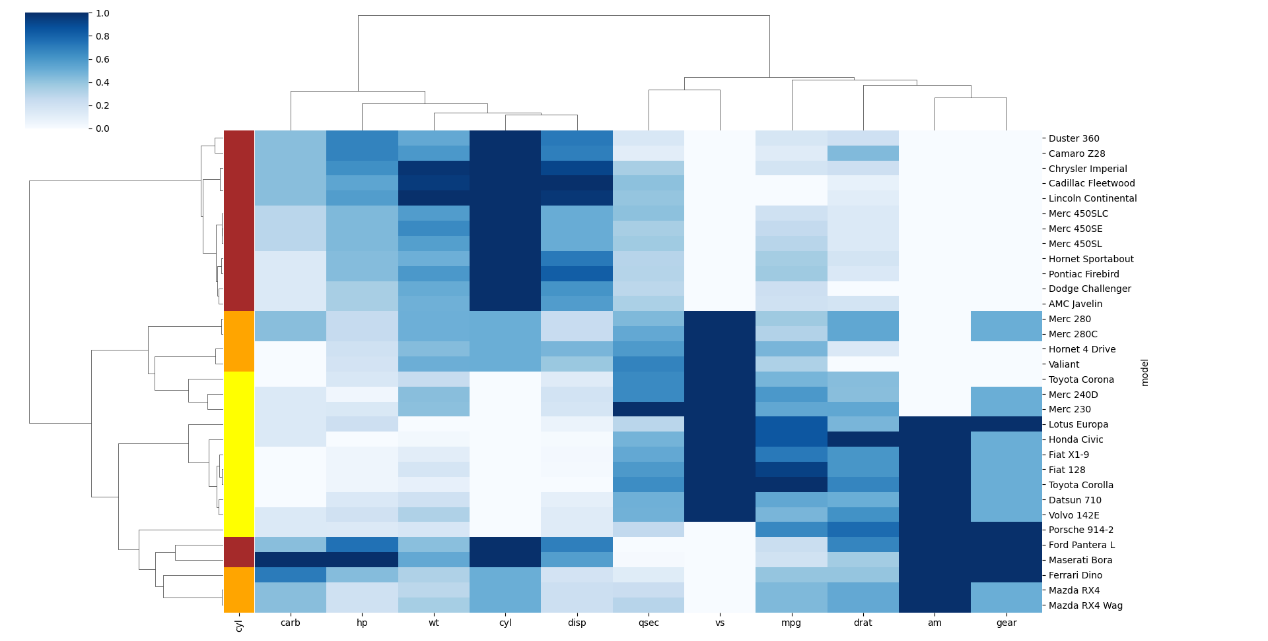
以上代码就是对绘制热图的介绍与Seaborn的基本使用方法,当然,大家也可以根据自己的需求和研究目标修改和调色哦!怎么样,你学会了嘛?
如果小伙伴有其他绘图需求,可以尝试使用本公司新开发的生信分析小工具云平台,零代码完成分析,非常方便奥,云平台网址为:(http://www.biocloudservice.com/home.html) ,可绘制表达量热图,和聚类热图等(http://www.biocloudservice.com/329/329.php,http://www.biocloudservice.com/365/365.php)各种小工具哦~,有兴趣的小伙伴可以登录网站进行了解。