高维数据如何预测分类?来试试这个简单好用又冷门的机器学习算法——LDA
生信人R语言学习必备
立刻拥有一个Rstudio账号
开启升级模式吧
(56线程,256G内存,个人存储1T)

很多小伙伴经常苦恼自己的文章用上什么方法可以显得与众不同呢?小果想来想去,终于想到了一个好用且冷门的机器学习算法!它就是一种用于数据降维以及分类预测的机器学习方法——LDA。是不是很少见过这个名字?今天就让小果带你一起来学习一下吧!
早期的LDA只能处理二分类问题,后来被拓展为了“多类别线性判别分析”又称“多元判别分析”,将LDA改进为多分类模型。那么它是如何降维的呢?其实LDA的本质就是将数据集投影到具有良好分类特征的低维空间上,投影后类内方差最小、类间方差最大,用于表征数据结构以及识别分类,因此它在高维数据集的分析中非常流行。与其它机器学习算法(例如神经网络、随机森林等)相比,LDA的主要优点是可更好避免过拟合以及计算简单。是不是感觉还不错?
多说无益,代码食用起来更佳,接下来小果将通过一个R语言实现鸢尾花分类预测的分析案例来带大家认识LDA 。分析流程主要分为四步:
Step1:导入相关包
Step2:数据准备
Step3:模型训练及预测
Step4:结果可视化
1.导入相关包
library(MASS)library(ggplot2)
2.数据准备
下图展示了鸢尾花数据的部分样本表达,每行代表一个样本,每列为其不同的特征,其中Species列为每个样本的种类,也是本次分析的目标特征。
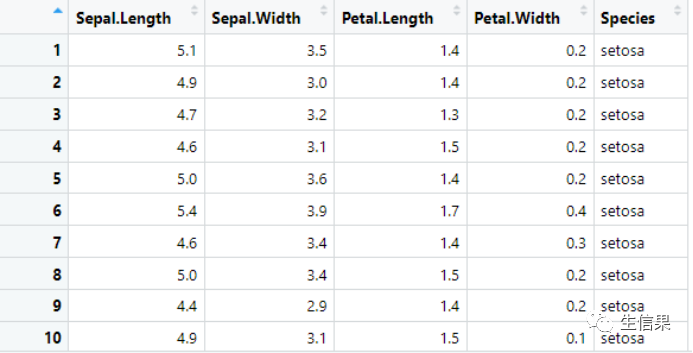
nx = 150#获取鸢尾花数据irisdata = iris[1:nx, 1:4]#获取鸢尾花分类结果irisgrp = iris[1:nx, 5]head(irisdata)
3.模型训练及预测
#模型搭建并训练lda.sol = lda(irisdata, irisgrp)#查看模型lda.sol#对数据的分类进行预测result=predict(lda.sol, irisdata)#展示预测分类结果table(irisgrp,result$class)P = lda.sol$scaling# 将均值向量降维means = lda.sol$means %*% P# 加权平均的出总的降维均值向量,权重就是lda.sol$priortotal_means = as.vector(lda.sol$prior %*% means)#获取所有样本个数n_samples = nrow(irisdata)# 把样本降维并平移x<-as.matrix(irisdata) %*% P - (rep(1, n_samples) %o% total_means)
4.结果可视化
#查看关键特征下的样本表达情况head(result)#使用ggplot方法对样本分类进行散点图绘制ggplot(cbind(irisdata, x), aes(LD1, LD2, color = irisgrp)) +geom_point() +stat_ellipse(level = 0.95, show.legend = FALSE)
5.分析结果展示

分类预测结果矩阵
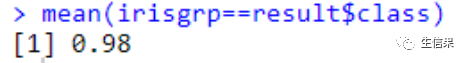
预测准确率
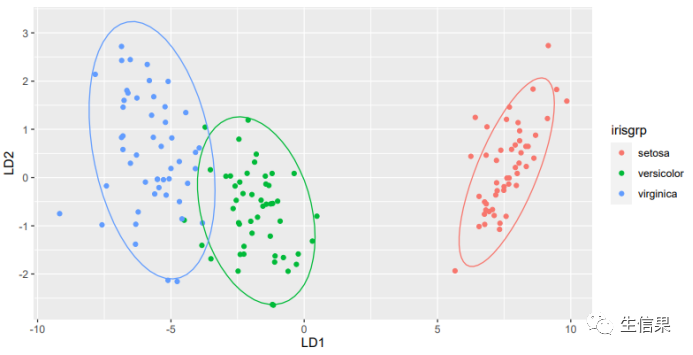
样本在LD1、LD2轴上的散点分布图
由分析结果图可以看出,约98%的数据可以被LDA模型分类到正确的类别,说明LDA分类器的精度是可靠的,且根据可视化结果所得散点图可以看出,样本被分为3类,其中不同颜色代表不同的样本种类,同时可以看到所有样本在LD1轴上具有较好区分度,说明LD1是最能体现出样本类间差异的重要特征,有了重要特征,小伙伴们就可以利用这个特征下的样本表达情况来自由发挥啦!
整个LDA分析流程到这里就结束啦,是不是很简单?但是也不要掉以轻心哦!最好还是亲自动手试一试,用自己手头的数据来试试LDA模型的降维效果以及分类预测的性能,说不定会有意想不到的惊喜哦!
如果小伙伴有其他数据分析需求,可以尝试使用本公司新开发的生信分析小工具云平台,零代码完成分析,非常方便奥,云平台网址为:(http://www.biocloudservice.com/home.html),其中也包括了通路表达分析(http://www.biocloudservice.com/313/313.php),单细胞的基因共表达分析(http://www.biocloudservice.com/906/906.php)等各种小工具哦~,有兴趣的小伙伴可以登录网站进行了解。
点击“阅读原文”立刻拥有
↓↓↓