师妹带学R语言之正则表达式
❤️点击蓝字关注我们
大家好,很高兴和大家见面啦!今天小师妹向大家介绍R语言正则表达式的相关内容,一起来学习吧!
R语言中的正则表达式是一种强大的文本处理工具,用于匹配和操作字符串。它可以通过一系列的符号和特殊字符来定义模式,从而实现对文本的搜索、替换和提取。R语言中常用的正则表达式函数有grep、grepl、sub和gsub等。正则表达式的基本匹配符号包括`.`、`^`和`$`,字符类包括`[]`,限定符包括`*`、`+`和`?`等。此外,R语言支持特殊字符和元字符的使用,如`d`、`w`和`s`等。正则表达式在R语言中广泛应用于数据清洗、文本分析和模式匹配等任务。
正则表达式中一个重要的元字符是方括号[]。两个方括号[]标定出来的由一系列
字符组成的列表叫做字符组。
正则表达式“[Tt]he”表示无论是The还是the都符合搜索要求,举个栗子:
 正则表达式”[a-z]at”表示aat、bat、cat…zat都符合搜索要求。例如:
正则表达式”[a-z]at”表示aat、bat、cat…zat都符合搜索要求。例如:

注意:[a-z]用连字符-把a和z连起来,说的是该字符组中包含了a到z的所有小写字母,一系列字符串可以通过给出第一个字符、最后一个字符
 ^开头表示否定
^开头表示否定正则表达式”at.”则表示所有长度为三个字母,前面两个字母是at的字符串都符合要求。而”at[.]”则表示只有当一个长度为三的字符串为”at.”才符合要求。比较一下这两个栗子:

大部分字符在字符组中都丧失了其特殊意义,其中只有三个元字符是例外,即^ – ]。在一个字符组中,元字符^只要不在最左边的位置,它就没有特殊意义;元字符}只要在最左边就没有特殊意义;而元字符-无论是在最左边还是在最右面都没有特殊意义。
序列符号
01
\d数字型字符 \D非数字型字符


02
\s间隔字符 \S非间隔字符


03
\w单词型字符 \W非单词型字符

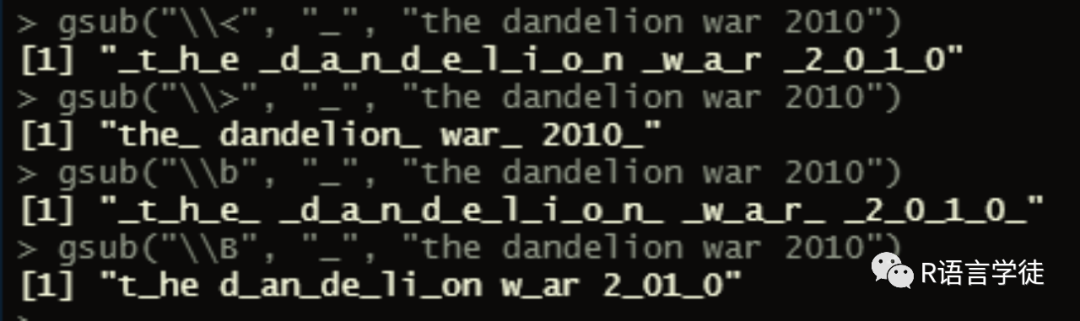
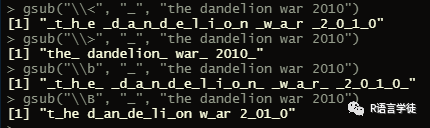
“\<” 用于匹配单词左侧边界的长度为零的字符串;\> 用于匹配单词右侧边界的长度为零的字符串;\b 用于匹配单词左右两侧长度为零的字符串;\B 用于匹配不出与单词边界的长度为零的字符串;
^用于匹配每一行开头的空白字符。
$用于匹配每一行结尾的空白字符。
|表示”或”的意思


?表示其前面项目不存在或只能存在一次。例如”at[.]?”表示字符串要包含两个字母at,其后可以包含一个英文句号.。
*表示其前面的项目可以被匹配零次或更多次。
+表示其前面的项目将被匹配一次或更多次。
{n}表示其前面的项目将仅被匹配n次
{n,}表示其前面的项目将被匹配n次或更多次
以上就是本期关于正则表达式的内容了,喜欢的话记得给小师妹点个赞哦。这里小师妹还想推荐一个小工具:单细胞数据绘制小提琴图(http://www.biocloudservice.com/788/788.php),在线运行,可以使用加载的数据来实践哦。
—————–⭐️—————-

