三分钟了解R中的管理数据函数
点
击
蓝
字
★
关
注
我
们
用R处理数据集的过程是分析过程中必不可少的一部分,今天小师妹借鉴《R语言实践》的第五章来一起探讨有关数据管理的内容。
首先了解常用的几种函数
数学函数

统计函数
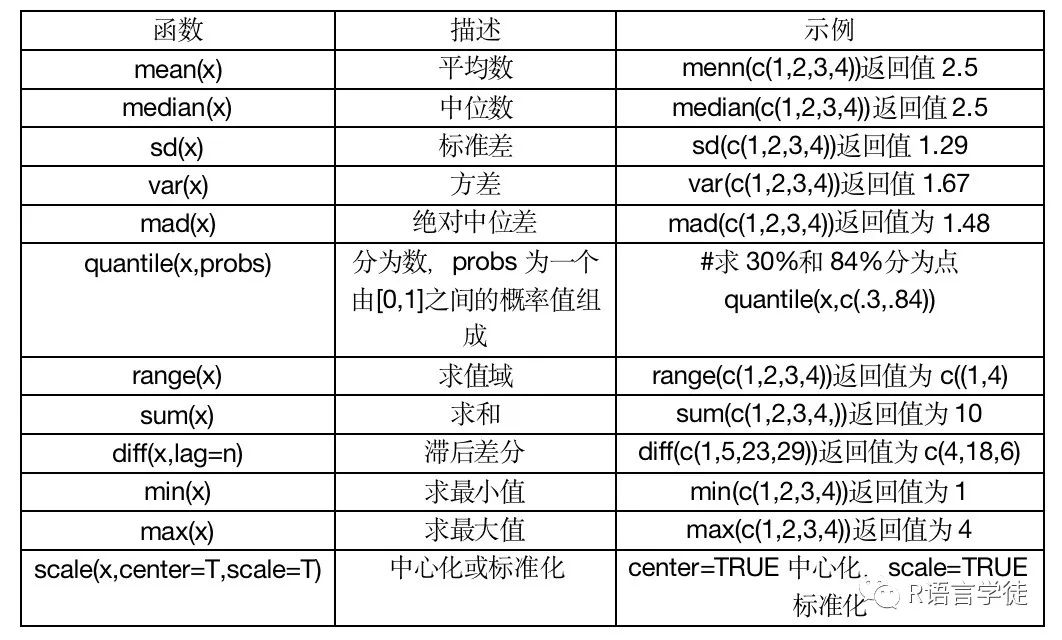
前文中提到的数学函数和统计函数都比较简单,但是小师妹也建议大家尝试一下加深对各个函数的了解~
概率函数
[dpqr]distribution_abbreviation()
d=密度函数(density)
p=分布函数(distribution function)
q=分位数函数(quantile function)
r=生成随机数(随机偏差)
例如runif(5)就是随机生成5个在[0,1]上均匀分布的随机数。
举例子来探索一下实际操作是怎么应用~
首先设定随机种子
通过set.seed()显示指定这个种子,可以让结果重现,体会这个函数的作用。

生成服从多元正态分布的数据
模拟研究和蒙特卡洛方法中,获取来自给定的均值向量和协方差阵的多元正太分布的数据。MultiRNG包中的draw.d.variate.normal(),可以实现,用法为
draw.d.variate.normal(no.row,d,mean.vec,cov.mat)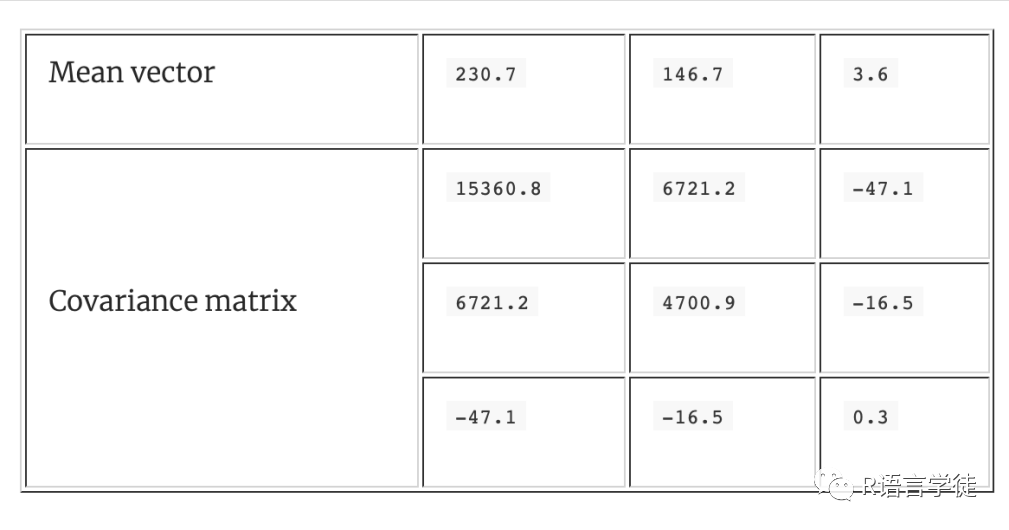
nstall.packages("MultiRNG")library(MultiRNG)options(digits=3)set.seed(1234)mean <- c(230.7, 146.7, 3.6)sigma <- matrix(c(15360.8, 6721.2, -47.1,6721.2, 4700.9, -16.5,-47.1, -16.5, 0.3), nrow=3, ncol=3)mydata <- draw.d.variate.normal(500, 3, mean, sigma)#指定想要的均值向量和协方差,随机生成500个伪随观测数值mydata <- as.data.frame(mydata)#转化为数据框的格式names(mydata) <- c("y","x1","x2")#为变量指定名称dim(mydata)head(mydata, n=10)
字符处理函数
常用的数据管理的函数
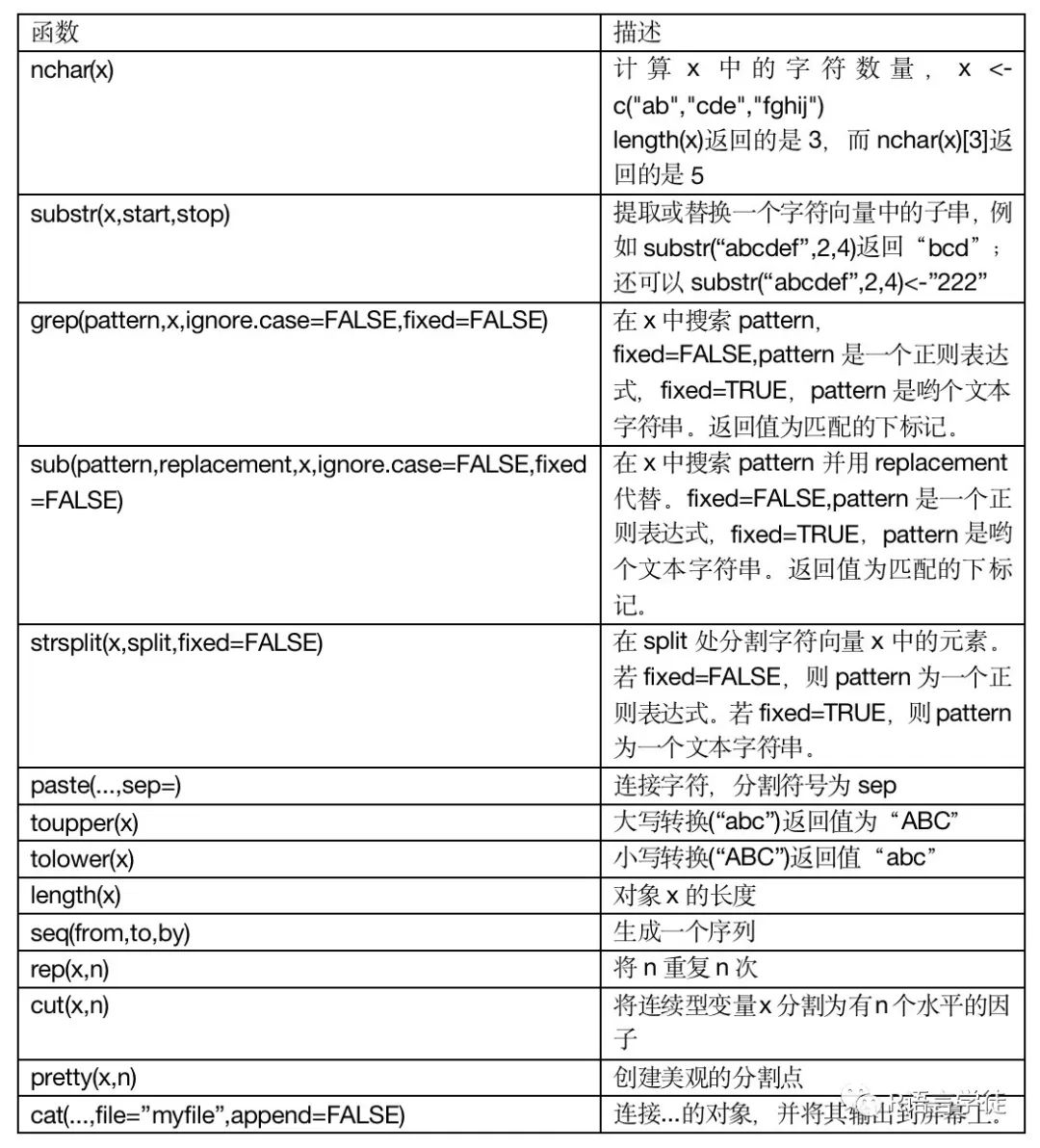
针对难理解的函数小师妹进行了尝试,其它的就留给你们自己尝试啦~
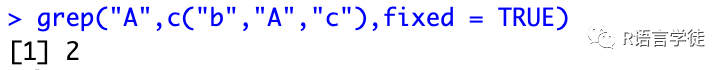


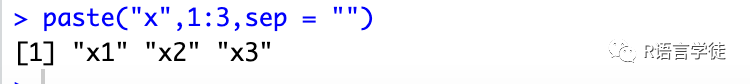

在数据处理过程中,R也开发了很多包例如reshpae2、tidyr等,但是都是基于基础的函数操作的,对于基础我们还是要理解掌握,然后学起各种各样的包也会得心应手些~
数据分析不会做,别忘了可以借助云平台http://www.biocloudservice.com/home.html
好了今天的分享就到这里啦~如果有问题可以与小师妹一起讨论哦~
★

