mlr3中的机器学习–进入生物信息学新时代(3)
点击蓝字 关注我们
2023 summer


在上一节中,小师妹带大家学习了mlr3中至关重要的learner方法,对应机器学习中的不同算法(如决策树、随机森林、支持向量机等)。小伙伴们现在已经学会了创建task机器学习任务,并通过learner进行学习、数据分区和预测 ,但是之前小师妹带大家使用的都是算法的默认参数进行学习,但是对于更为精细的机器学习任务,避免不了超参数调优,只有选择合适的机器学习超参数,才能创建更为科学、合理的模型。
机器学习算法通常包括参数和超参数。参数是模型系数或权重或其他信息,由学习算法基于训练数据进行优化确定。相反,超参数由用户配置,并确定模型将如何适合其参数,即模型如何构建。示例包括设置随机森林中的树数、支持向量机中的惩罚设置或神经网络中的学习率。
Learners方法封装了机器学习算法及其超参数,这些参数会影响算法的运行方式,同时可由用户进行设置。超参数通常会影响模型的训练方式或预测方式,决定如何设置超参数可能需要专业知识。

在本节中,小师妹将教会大家如何手动调整超参数,并对设定好的机器学习模型进行性能评估,即判断模型预测的质量是否”良好”。首先,让我们导入mlr3包:
library(mlr3) 一#
2023
一.超参数概览
在进行一个模型的超参数设定之前,我们需要知道模型具体有哪些可以调整的超参数,超参数的名称、参数类型、默认取值和参数空间等。
小师妹将带大家使用决策树learner进行演示,可以使用$param_set来访问learner中的超参数:
lrn_rpart = lrn("regr.rpart")lrn_rpart$param_set
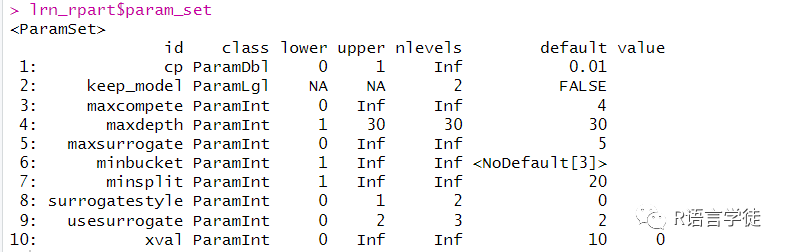
该输出的第一列(id)是超参数的名称,第二列(class)是超参数的类型,第三列第四列(lower,upper)是超参数的上界和下界,第五列(nleverls)是指其可能的取值数量,Inf代表无穷多(大),default是超参数的默认值,value是设定值。
从上面的示例中,从输出中我们可以判断:
-
cp是双精度实数,取值介于(0,1),默认值为0.01
-
keep_model是布尔变量,其默认值为FALSE(0)
-
xval是整数变量,取值介于,默认值为10
-
……
二#
2023
获取和设置超参数
经过上面的讲解,小伙伴们有没有明白超参数值是如何存储的呢?现在,我们要考虑如何获取并设置它们。例如我们的决策树模型,假设我们现在想要创建一个有深度的树,其中数据仅被拆分成为两个终端节点一次。
下面的几种方法可以更改该超参数:
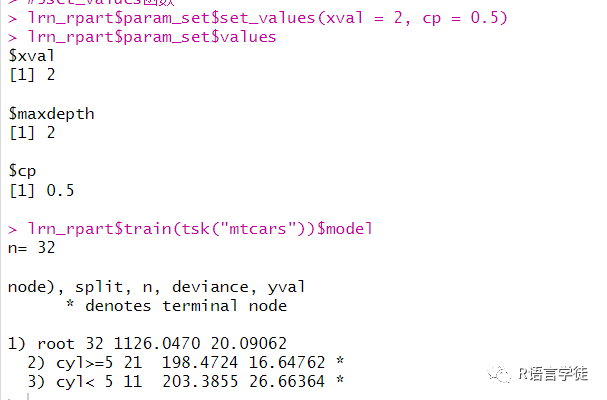
#更改超参数#1通过learner方法修改lrn_rpart = lrn("regr.rpart", maxdepth = 3, xval = 1)lrn_rpart$param_set$valueslrn_rpart$train(tsk("mtcars"))$model#2更新列表lrn_rpart$param_set$values$maxdepth = 2lrn_rpart$param_set$valueslrn_rpart$train(tsk("mtcars"))$model#3set_values函数lrn_rpart$param_set$set_values(xval = 2, cp = 0.5)lrn_rpart$param_set$values
其中,第一种方法,通过在lrn()函数中设定超参数的取值,可以更改超参数;在第二种方法中,我们通过获取param_set列表中的values,设定maxdepth=2;在第三种方法中,通过param_set中的set_values()函数,可以更改多个超参数。
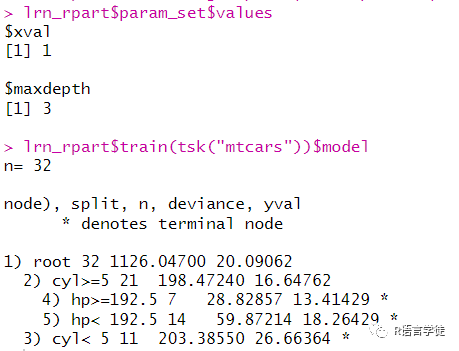
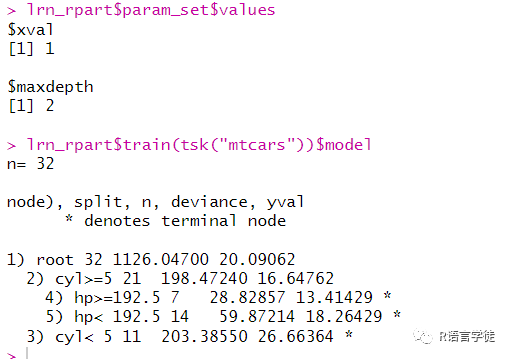
在learner中,存在一种已经设定好超参数的模型,虽然这种模型在实际应用中通常不会去选择,但在整个建模的过程中具有重要的意义。我们叫它基线学习者,基线学习者在模型比较等步骤中具有重要的意义。
df = as_task_regr(data.frame(x = runif(1000), y = rnorm(1000, 2, 1)),target = "y")#生成datalrn("regr.featureless")$train(df, 1:995)$predict(df, 996:1000)
一般来说,性能比基线学习者差的,我们认为是坏的模型,另一方面,性能比基线学习者好的,不一定是好的模型。
三#
2023
模型的评价
在整个机器学习工作的流程中,最重要的步骤可能是模型的性能评估。没有性能的评估,我们将无法知道所训练的模型是否进行了精准的预测,还是比随机猜测更为糟糕,或者介于两者之间。在下面的例子中,小师妹仍将使用决策树模型来确定预测的质量是否“良好”,进而对模型给出相应的评价。
#模型评价lrn_rpart = lrn("regr.rpart")tsk_mtcars = tsk("mtcars")splits = partition(tsk_mtcars)lrn_rpart$train(tsk_mtcars, splits$train)prediction = lrn_rpart$predict(tsk_mtcars, splits$test)
评价的准则通常有以下几种:

其中,常见的aic、bic相信大家都有所耳闻,实施的所有措施主要由三个组成部分定义:1)定义措施的函数;2)较低或较高的值是否被视为“良好”;3)措施可以采取的可能值的范围。
小师妹将在示例中,向大家演示通过平均绝对误差(MAE)来进行模型评估:
#评价准则列表as.data.table(msr())measure = msr("regr.mae")measure

平均绝对误差(Mean Absolute Error,简称MAE)是机器学习和统计学中常用的度量标准,用于衡量预测值与实际值之间误差的平均大小,它提供了一种简单的方式来量化预测模型的整体准确性。
平均绝对误差(MAE)的计算公式如下:

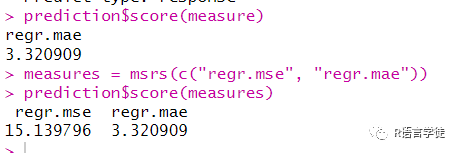
下面,我们将计算模型的MAE,也可以同时计算多个评价准则:
#计算MAEprediction$score(measure)#计算MAE、MSEmeasures = msrs(c("regr.mse", "regr.mae"))prediction$score(measures)
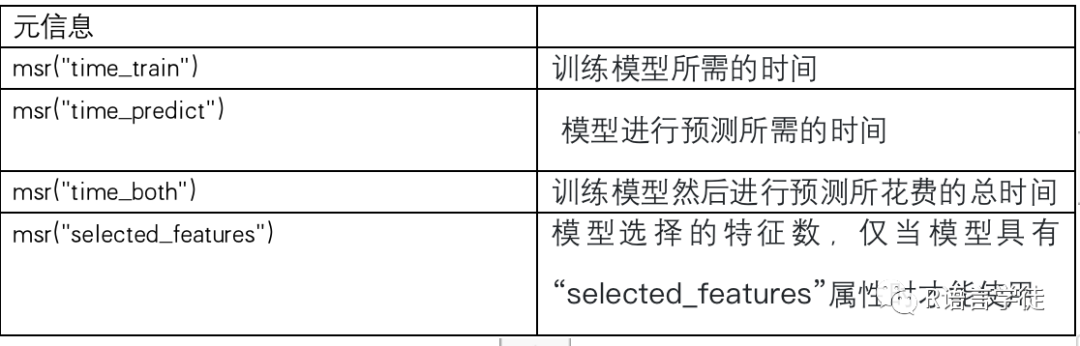
Mlr3中不仅提供了模型预测结果的评价准则,还有一系列跟模型有关的元信息:
最后
到这里,今天的内容小师妹就向大家讲完了,不知道同学们是否学会了呢,在小师妹的陪伴下,相信小伙伴们已经基本掌握了机器学习中的超参数和评价相关的知识,会通过R语言编写相应的程序,小师妹要和大家说再见咯,一定要自己练习一下哦,同时如果大家想要继续了解更多有关R语言内容可以持续关注小师妹哦~~或者也可以关注我们的官网也会持续更新的哦~ http://www.biocloudservice.com/home.html

