mlr3中的机器学习(5)——运用重采样方法进行模型评估
“ 点击蓝字 / 关注我们 ”
小师妹又和大家见面啦!相信看到这篇文章的小伙伴们,已经在前面的学习中,学会了通过R语言中的mlr3包进行简单的机器学习任务,并取得了一点点小小的成果,今天,小师妹将向大家介绍在机器学习和统计学中一个至关重要的技术——重采样:

通过重采样策略(从维持到交叉验证和引导),我们可以估计模型的泛化性能。在监督学习的过程中,模型只有在具有良好的泛化能力的情况下才能在实践中得到部署,泛化能力代表着模型预测新的、看不见的数据的能力。准确估计泛化能力对于机器学习应用和研究起到了至关重要的作用。在机器学习领域,重采样方法可以有效地对模型的泛化能力进行估计。它可以用于模型评估与选择,通过对原始数据进行重抽样来减少评估偏差,还可用于参数估计与置信区间估计,帮助评估模型参数的不确定性。重采样在集成学习中也扮演重要角色,如随机森林,通过构建多个模型并整合结果提高模型性能。此外,重采样方法还能用于异常检测,通过在多次训练中识别出在不同子样本中表现异常的数据点。最后,它还能提供预测的不确定性估计,为预测结果的可靠性提供更精准的评估。重采样方法在机器学习中为模型评估、参数估计、集成学习、异常检测和不确定性估计等方面提供了实用工具。
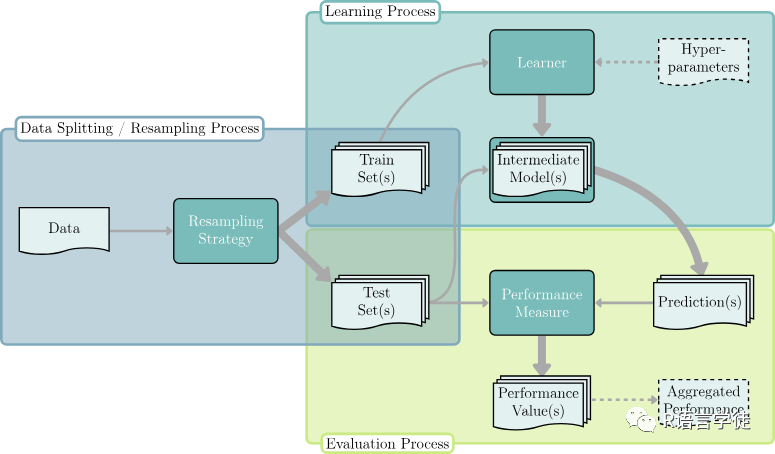
那么,重采样是怎么进行的呢?
首先,我们可以采用一种策略,将可用数据多次划分为不同的训练集和测试集,这被称为”重采样迭代”。在每个迭代中,利用一个训练集构建一个中间模型,并在对应的测试集上度量性能。通过聚合多次迭代的性能得分,可以估算泛化性能。通过多次的数据划分和迭代,同一数据点可以被多次用于训练和测试,从而充分利用所有可用数据进行性能估计。由于大量的迭代可以减小得分的差异,从而得到更可靠的性能估计。这意味着性能估计不太可能受到“不幸”划分的影响,如那些未能反映原始数据分布的划分。
有哪几种重要的重采样方法呢?
首先是K折交叉验证,它将原始数据集分成k个近似大小的子集,被称为“折”(folds)。然后,模型会进行k次训练和测试,每次训练时使用k-1个折作为训练集,剩余的1个折作为测试集。这个过程会k次迭代,以保证每个折都被用作测试集一次。最后,将每次迭代的性能指标(如准确率、误差等)进行平均,得到模型的最终性能评估。
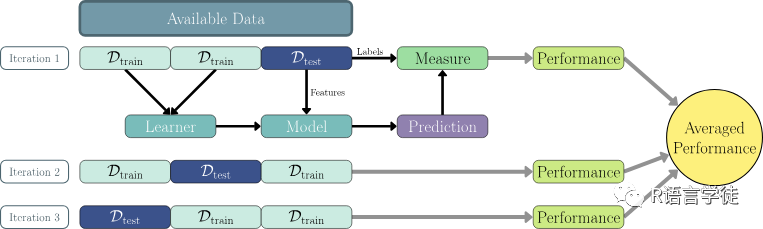
蒙特卡洛交叉验证(子抽样)也是一种不错的方法。与传统的k折交叉验证不同,蒙特卡洛交叉验证不是将数据划分为固定的折,而是通过多次随机抽样来进行训练和测试。
Bootstrap方法是一种古老的统计学重采样方法,从原始数据集中有放回地抽取多个样本,每次抽取的样本大小不一定与原始数据集相同,且可能包含重复的观测。利用新的观测作为新的样本进行机器学习任务的构建。
那么,下面小师妹将带大家通过R语言学习mlr3中的重采样技术!
首先我们导入需要的R包:
library(mlr3) 一.构建重采样策略
可以通过mlr_resamplings函数读取mlr3包中存储了哪些具体的重采样方法,
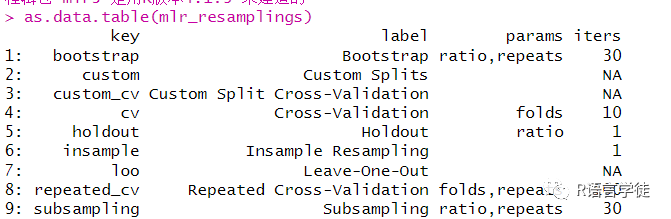
其中,第一列表示重采样方法的关键字,即我们在选取重采样方法的时候需要指定的对象,第二列是重采样方法的全名,第三列是使用该重采样方法需要输入的参数,第四列是在默认情况下执行重采样方法的迭代次数。
可以通过将具体的”key”和相应的参数传递给函数rsmp(),从而使用重采样方法。
as.data.table(mlr_resamplings)# 三折交叉验证cv3 = rsmp("cv", folds = 3)# 子抽样 (将样本划分为9:1,并重复3次)ss390 = rsmp("subsampling", repeats = 3, ratio = 0.9)# 两次五折交叉验证rcv25 = rsmp("repeated_cv", repeats = 2, folds = 5)
可以通过instantiate()函数在给定任务上调用该方法来手动实例化重采样策略,即生成所有训练-测试拆分。因此,小师妹带大家使用penguins任务,实例化三折 CV对象,然后使用$train_set和$test_set进行索引

tsk_penguins = tsk("penguins")set.seed(124)cv3$instantiate(tsk_penguins)#使用tsk_penguins进行交叉验证# 第一折训练集的前10个样本cv3$train_set(1)[1:10]# 第二折测试集的前5个样本cv3$test_set(2)[1:5]
通过上述构造重采样策略的方法,我们就可以轻松将样本分成三份,并每次将其中的一份作为测试集,其余两份作为训练集,对数据进行多组重构。
二.构建重采样实验
可以通过resample()函数,分别输入test,learner和相应的重采样策略,构造一组重采样实验,在训练集上反复拟合模型,并在相应的测试集上进行测试。
#重采样实验lrn_rpart = lrn("classif.rpart", cp = 0.2, maxdepth = 5)r1 = resample(tsk_penguins, lrn_rpart, cv3)acc = r1$score(msr("classif.ce"))accr1$aggregate(msr("classif.ce"))r1$aggregate(msr("classif.ce", average = "micro"))

可以将该函数的输入当成简单机器学习实验中的predict对象,并提取相应的评价得分。
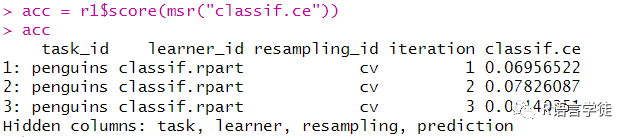
可以通过$aggregate返回模型的总得分,在这个例子中,即三次实验的acc平均数,
SUMMER of 2021
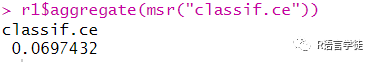
也可以通过在$aggregate中指定average = “micro”,最后将输出微观平均值,即将三次实验看成一次,在实验中的每个样本中求分数平均。事实上,可以通过计算很简单地验证,如果测试集都具有相同的大小,那么微观和宏观方法将是相同的。
SUMMER of 2021

返回的总得分可以估计我们所选learner在给定task上的泛化性能,使用对象中定义的重采样策略。虽然通常对聚合分数感兴趣,但查看每个重采样迭代(由方法返回)的各个性能值也很有用。
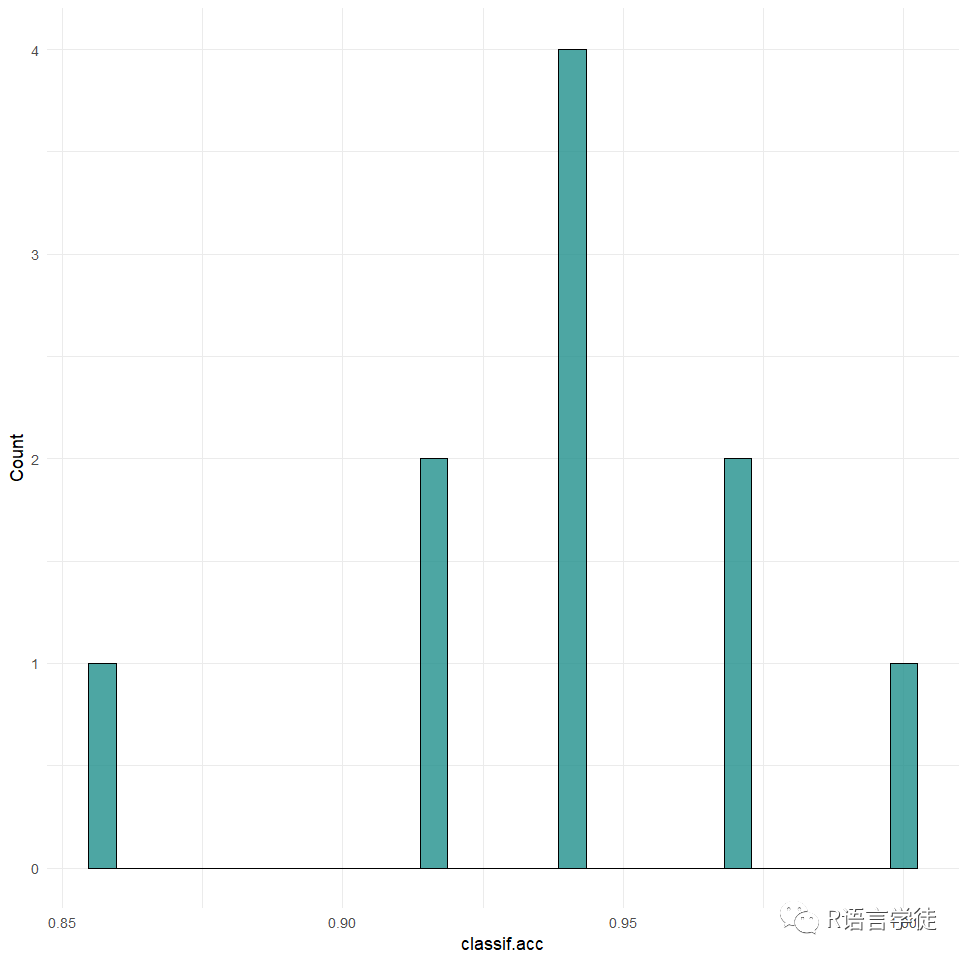
最后可以使用mlr3viz包进行重采样结果的可视化,进而评估模型的效果:
SUMMER of 2021
#可视化library(mlr3viz)rr = resample(tsk_penguins, lrn_rpart, rsmp("cv", folds = 10))autoplot(rr, measure = msr("classif.acc"), type = "boxplot")autoplot(rr, measure = msr("classif.acc"), type = "histogram")
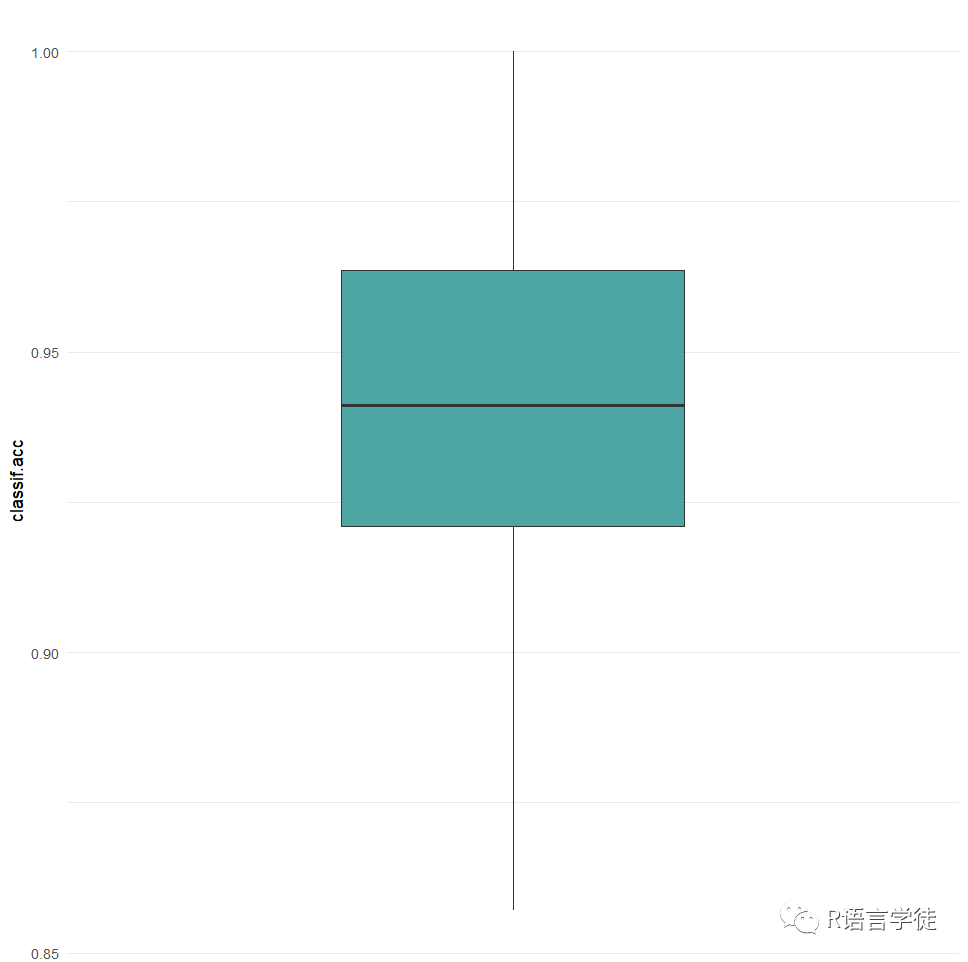
有关重采样知识的学习就到这里结束啦,小伙伴们是否学会了呢,希望课下大家可以打开R语言一起练习哦。小师妹要和大家说再见咯,一定要自己练习一下哦,同时如果大家想要继续了解更多有关R语言内容可以持续关注小师妹哦~~或者也可以关注我们的官网也会持续更新的哦~ http://www.biocloudservice.com/home.html

