mlr3中的机器学习–进入生物信息学新时代(2)
点击蓝字 关注我们

以下是一些关于 Learner 对象的重要信息:
1算法选择:mlr3 提供了多个内置的 Learner 对象,涵盖了常见的机器学习算法,包括分类、回归、生存分析等。你可以根据问题的性质选择合适的 Learner 对象。
2参数设置:每个 Learner 对象有一组默认的参数配置,这些参数会影响算法的行为和性能。你可以通过修改参数来调整算法的表现,也可以使用超参数优化方法找到最佳配置。
3训练与预测:Learner 对象有 train() 方法,用于从任务对象中训练模型。训练后的模型可以用于预测新数据。预测使用 predict() 方法,通过传入输入数据进行预测。
4性能评估:Learner 对象可以与不同的评估器(Resampler)一起使用,用于评估模型的性能。评估器可以执行交叉验证、留一法等策略来估计模型的性能指标。
5模型比较:Learner 对象可以用于进行模型比较和选择。你可以在同一任务上训练多个不同的模型,然后使用评估器比较它们的性能。
6自定义学习器:除了内置的 Learner 对象,你还可以创建自定义的学习器,用于集成其他机器学习库中的算法。这可以通过继承 Learner 类来实现。

首先先导入R包,然后使用mlr_learners相看mlr3中存储的机器学习方法,并通过lrn()函数读取特定的方法:
library(mlr3)mlr_learners#读取learner对象lrn("regr.rpart")#索引具体的learner对象
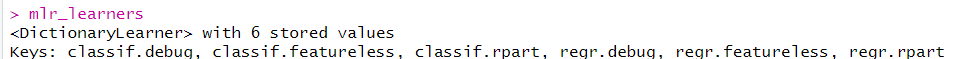

所有对象都包含以下元数据,可以在上面的输出中看到:Learner
$feature_types:learner可以处理的数据类型。$packages:使用learner需要安装的软件包。$properties:learner的属性。例如,“缺失”属性表示模型可以处理缺失的数据,“重要性”表示它可以计算每个特征的相对重要性。$predict_types:模型可以做出的预测类型$param_set:可用超参数的集合
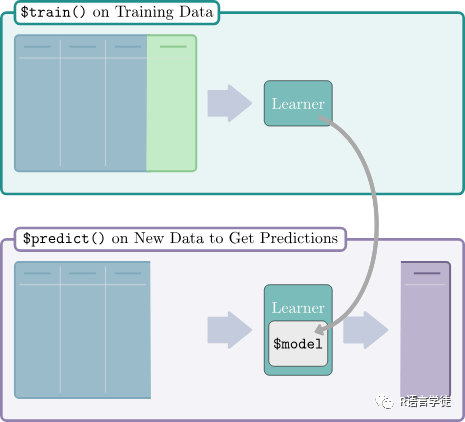
运行机器学习实验,learner需要经历两个阶段:
1训练Task$train():将训练传递给learner的函数,该函数可以训练和存储模型,即特征与目标的学习关系。
2预测$predict():新数据(可能是原始数据集的不同分区)被传递给经过训练的学习者的方法以预测目标值。
一
训
练
在下面的例子中,我们将通过$train()方法将task传给给learner进行模型的训练:
# 载入tasktsk_mtcars = tsk("mtcars")# 选择learner方法lrn_rpart = lrn("regr.rpart")# 将task传递给learner,从而进行模型的训练lrn_rpart$train(tsk_mtcars)lrn_rpart$model#输出训练后的模型

在这里小师妹使用机器学习中最为简单的决策树方法,对mtcars数据集进行学习,并输出lrn_rpart 学习器(R中的rpart算法)在mtcars数据集上训练后的决策树模型。其中,n= 32:表示训练数据的样本数量为32个。
Node, split, n, deviance, yval:这一行列出了树中每个节点的相关信息,其中:node 表示节点编号。split 是该节点分裂所用的特征。n 是该节点的样本数量。deviance 表示在该节点的不纯度或拟合误差度量。yval 是该节点的预测输出值。
* denotes terminal node:这表示 * 标志的节点为叶节点,即决策树的最终输出节点。
树的结构:根节点 (root):样本数为32,平均预测值 (yval) 为 20.09062。第二个节点 (cyl >= 5):满足条件 cyl >= 5 的样本有21个,平均预测值为16.64762。子节点 hp >= 192.5:满足条件 hp >= 192.5 的样本有7个,平均预测值为13.41429。由于没有更多的分裂条件,这个节点成为叶节点。子节点 hp < 192.5:满足条件 hp < 192.5 的样本有14个,平均预测值为18.26429。同样,这个节点也成为叶节点。第三个节点 (cyl < 5):不满足条件 cyl >= 5 的样本有11个,平均预测值为26.66364。这个节点也成为叶节点。
在这个例子中,我们看到决策树已经识别了任务中预测目标的特征,并使用它们对观测值进行分区。模型的文本表示取决于学习者的类型。
二
数
据
分
区
在机器学习任务中,当评估模型预测的质量时,通常希望对数据集进行分区,以获得对模型泛化误差的公平和公正的估计。数据集分区的方法通常由:拆分、重采样和基准测试实验。现在,我们将讨论使用 partition()函数拆分数据的最简单方法。Partition()函数创建索引集,将给定任务随机拆分为两个不相交的集:训练集(默认占总数据的 67%)和测试集(剩余 33% 的总数据不在训练集中)。
#数据分区splits = partition(tsk_mtcars)splitslrn_rpart$train(tsk_mtcars, row_ids = splits$train) #用分区后的数据进行训练
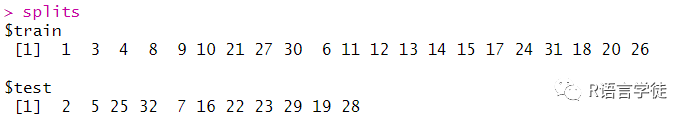
训练时,我们将通过方法将行 ID 从 传递给参数,告诉模型仅使用训练数据。这样,我们就可以使用训练数据进行训练并使用预测数据进行模型的评估。
三
预
测
下面小师妹将带小伙伴们学习模型的预测,也非常简单呢,只需使用Task$predict()Learner就可以了:
#预测prediction = lrn_rpart$predict(tsk_mtcars, row_ids = splits$test)predictionprediction$response[1:2]

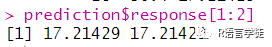
prediction = lrn_rpart$predict(tsk_mtcars, row_ids = splits$test):使用 lrn_rpart 学习器的 predict() 方法来在测试集上进行预测。tsk_mtcars 是我们创建的回归任务对象,row_ids = splits$test 指定了在测试集上进行预测。
prediction:这行代码打印了预测的结果。这将是一个包含预测输出的对象,其中包括一些与预测相关的信息,例如每个样本的预测值。
prediction$response[1:2]:这行代码通过样本ID(行ID)的索引,展示了预测结果中前两个样本的预测响应(预测值)。这样可以查看测试集中的前两个样本在模型上的预测结果。
同样可以通过可视化更为直观地给出模型的预测,mlr3viz 包为prediction对象提供了一个 autoplot() 方法,给出预测值和真实值的比较,同时还会给出预测值的预测区间:
#预测结果的可视化library(mlr3viz)prediction = lrn_rpart$predict(tsk_mtcars, splits$test)autoplot(prediction)
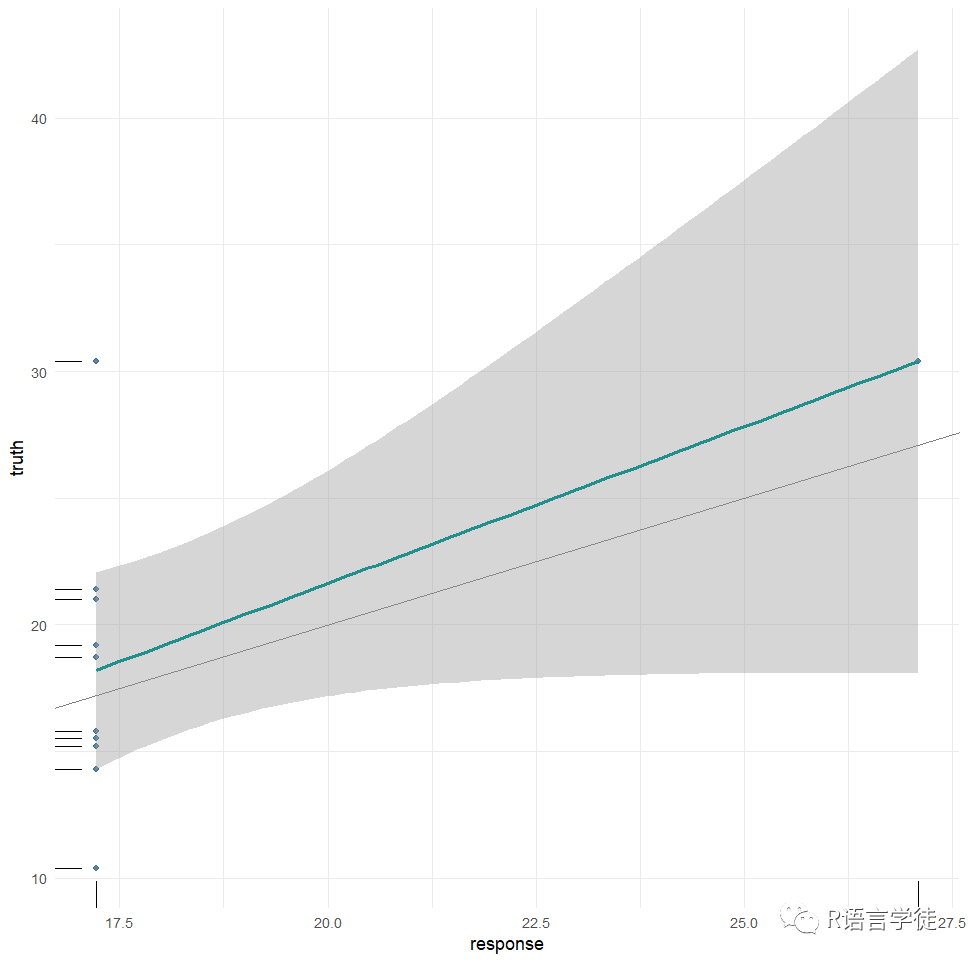
上面的例子,小师妹以一个task作为传递来进行预测。同理,可以传递R语言中的数据对象,可以通过$predict()data.frame$predict_newdata()
#传递数据集进行预测mtcars_new = data.frame(cyl = c(5, 6), disp = c(100, 120),hp = c(100, 150), drat = c(4, 3.9), wt = c(3.8, 4.1),qsec = c(18, 19.5), vs = c(1, 0), am = c(1, 1),gear = c(6, 4), carb = c(3, 5))prediction = lrn_rpart$predict_newdata(mtcars_new)prediction
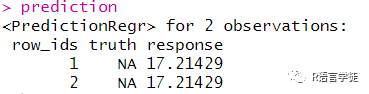
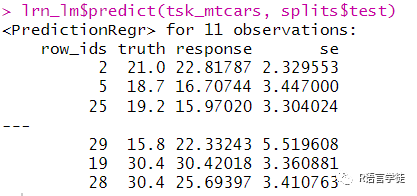
通常的预测类型是预测变量分布的均值,也可以指定预测变量的标准误差。如果想要预测变量的标准误,需要在训练之前即选择方法的时候就将预测类型指定:
#预测标准误library(mlr3learners)lrn_lm = lrn("regr.lm", predict_type = "se")lrn_lm$train(tsk_mtcars, splits$train)lrn_lm$predict(tsk_mtcars, splits$test)
到这里,learner方法的基本属性和有关操作小师妹就向大家讲完了,不知道同学们是否学会了呢,在小师妹的陪伴下,相信小伙伴们已经基本掌握了mlr3中learner方法的相关知识,会通过R语言编写相应的程序,小师妹要和大家说再见咯,一定要自己练习一下哦,同时如果大家想要继续了解更多有关R语言内容可以持续关注小师妹哦~~或者也可以关注我们的官网也会持续更新的哦~ http://www.biocloudservice.com/home.html

