五分钟R语言例题实战,助你掌握R语言
{ 点击蓝字,关注我们 }
大家好,本期小师妹将通过几道题目帮助大家更好地掌握之前介绍过的知识。
第一题:合并不同数据类型的向量,并告诉我向量合并后的数据类型是什么?
char_vector<-c("zhangsan","lisi","wangwu")num_vector<-c(1,2,3)combined_vector<-c(char_vector,num_vector)combined_vector###合并后的向量包含了字符类型和数值类型的数据,但是数值类型的数据被转换成了字符类型。

第二题:x是-1到1之间均匀分布的长度为100的向量,请写程序定义一个向量y,y=1-x,x<0;y=1+x,x>=0
x<-runif(100,-1,1)get_y<-function(x){ifelse(x<0,1-x,1+x)}y<-get_y(x)y

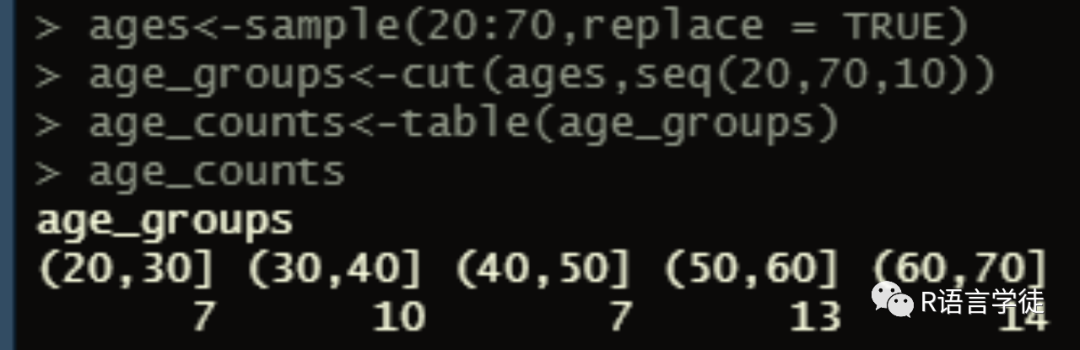
#3.写程序定义变量ages,表示100个20~70岁的成年人年龄,并以每10岁作为区间统计各个年龄段的人数
ages<-sample(20:70,replace = TRUE)age_groups<-cut(ages,seq(20,70,10))age_counts<-table(age_groups)age_counts
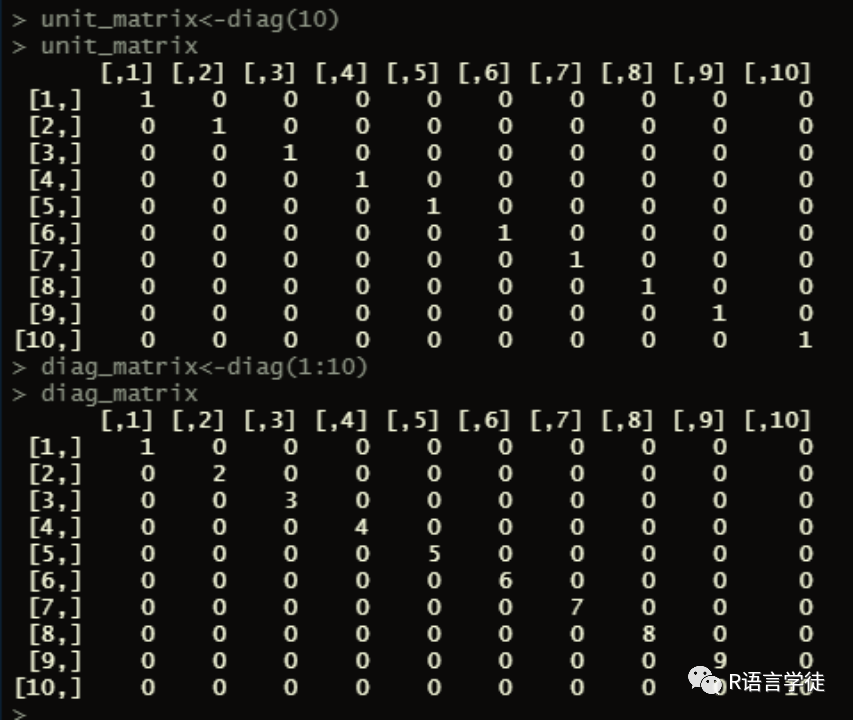
#4.写程序生成10*10的单位矩阵和对角线上分别为1:10的对角矩阵
unit_matrix<-diag(10)unit_matrixdiag_matrix<-diag(1:10)diag_matrix
#5.写程序生成如下矩阵,并用apply命令按列进行求和
A<-matrix(c(NA,9,17,25,3,NA,19,27,5,13,NA,29,7,15,23,NA),ncol=4)Aapply(A, 2, sum,na.rm=T)

#6.利用R内部mtcars数据,计算mpg、 drat和wt列数据的中位值(median)、平均值(mean)及标准差(sd);并按cyl分组,计算不同组别的mpg、 drat和wt列数据的平均值(mean)
library(dplyr)mpg_median <- median(mtcars$mpg)mpg_mean <- mean(mtcars$mpg)mpg_sd <- sd(mtcars$mpg)drat_median <- median(mtcars$drat)drat_mean <- mean(mtcars$drat)drat_sd <- sd(mtcars$drat)wt_median <- median(mtcars$wt)wt_mean <- mean(mtcars$wt)wt_sd <- sd(mtcars$wt)mtcars %>%group_by(cyl) %>%summarise(mpg_mean = mean(mpg), drat_mean = mean(drat), wt_mean = mean(wt))

#7.写程序生成从1到100的整数,若数字为7的倍数,打印数字,若数字为9的倍数,打印’NA’ ,其余情况不输出。
for (i in 1:100) {if (i %% 7 == 0) {cat(i, "n")} else if (i %% 9 == 0) {cat("NA", "n")}}

#2.写程序输出下三角表示的九九乘法表。
# 生成九九乘法表result <- matrix(0, nrow = 9, ncol = 9)for (i in 1:9) {for (j in 1:i) {result[i, j] <- i * j}}# 打印下三角形式的九九乘法表for (i in 1:9) {for (j in 1:i) {cat(i,'*',j,'=',result[i, j], "t")}cat("n")}
以上就是本期小师妹带学的内容啦。请持续关注小师妹,我们下期见~
筛选免疫基因对小工具:www.biocloudservice.com/589/589.php
E
N
D

