临床分析你不能不会的技能之DCA决策曲线分析
点击蓝字,关注我们
DCA(Decision Curve Analysis)是一种曲线分析方法,用于评估预测模型的临床应用价值。DCA可以帮助医学研究人员和临床医生在不同预测模型之间做出最优选择,以达到更好的临床预测效果。DCA可以评估不同预测模型在临床应用中的效益,例如癌症筛查、疾病预后和药物治疗等。在癌症筛查中,DCA可以评估不同筛查模型的临床应用价值,以帮助医生在不同筛查模型之间做出最优选择。在疾病预后中,DCA可以评估不同预测模型的应用价值,以帮助医生做出更准确的预后预测和治疗决策。
DCA的核心思想是通过绘制决策曲线来比较不同预测模型在不同治疗决策阈值下的临床效益。决策曲线显示了在不同治疗决策阈值下,使用预测模型进行治疗决策所获得的利益。利益可以定义为治疗正确的病例数减去治疗错误的病例数,其中治疗正确指的是根据预测模型的输出结果进行正确的治疗决策。
在DCA中,首先确定一个参考策略作为比较基准,例如不治疗、全面治疗等。然后,将不同预测模型的决策曲线与参考策略进行比较,以确定哪个预测模型在不同治疗决策阈值下具有更高的临床效益。
DCA的优势在于它不仅考虑了模型的灵敏性和特异性,还考虑了不同决策阈值下的治疗效果和副作用,从而可以更全面地评估预测模型的实用性和临床应用价值。DCA适用于评估任何类型的预测模型,包括临床评分、生物标志物、基因组学、蛋白组学、影像学等各种类型的预测模型。
DCA的原理基于利益(Net Benefit)的概念,其核心思想是通过比较不同统计模型的利益来选择最佳模型。利益可以定义为治疗正确的病例数减去治疗错误的病例数,其中治疗正确指的是根据预测模型的输出结果进行正确的治疗决策。
在DCA中,首先需要确定一个参考策略,例如不治疗或全面治疗。然后,将预测模型的决策曲线与参考策略进行比较,以确定预测模型在不同治疗决策阈值下的优劣。决策曲线显示了在不同治疗决策阈值下,使用预测模型进行治疗决策所获得的利益。
在DCA中,利益是由四个参数决定的:预测模型的灵敏性、特异性、治疗收益和治疗风险。其中,灵敏性和特异性是预测模型的两个基本指标,治疗收益和治疗风险是治疗决策的两个关键因素。利益可以表示为以下公式:
Net Benefit = (True Positive Rate × Treatment Benefit) – (False Positive Rate × Treatment Harm)
其中,True Positive Rate(真阳性率)指的是预测模型正确地识别需要治疗的病例数占总需要治疗的病例数的比例;False Positive Rate(假阳性率)指的是预测模型错误地将不需要治疗的病例识别为需要治疗的病例的比例;Treatment Benefit(治疗收益)指的是治疗正确时获得的利益;Treatment Harm(治疗风险)指的是治疗错误时造成的损失。
DCA的目的是绘制决策曲线,以比较不同预测模型在不同治疗决策阈值下的利益。决策曲线是将预测模型的灵敏性和特异性作为横轴,利益作为纵轴的曲线。参考策略的利益为0,即其决策曲线始终位于x轴以下。在DCA中,预测模型的决策曲线越靠近参考策略的决策曲线,说明该预测模型的临床实用性越低。相反,如果预测模型的决策曲线在参考策略的决策曲线之上,则说明该预测模型的临床实用性更高。
总的来说,DCA的原理是通过利益比较来选择最佳预测模型,利用决策曲线来比较预测模型在不同治疗决策阈值下的临床效益,从而帮助医学研究人员和临床医生在不同预测模型之间做出最优选择。
接下来小师妹将手把手教会大家在R中使用DCA,这里主要使用rmda 和 ggDCA这两个包。
library(rmda)library(ggDCA)library(ggplot2)library(rms)library(caret)data(dcaData)head(dcaData)

#模型构建#构建一个单变量的baseline模型set.seed(123)baseline.model <- decision_curve(Cancer ~ Age + Female + Smokes, data = dcaData,thresholds = seq(0, 0.4, by = 0.005), bootstraps = 10)plot_decision_curve(baseline.model,curve.names = "Baseline Model",cost.benefit.axis =FALSE,#col= c('red','blue'),confidence.intervals=FALSE,standardize = FALSE)

注意,这里”all”和”none”是两种参考策略,用于比较预测模型的效益。”all”参考策略意味着在所有情况下都进行治疗,而”none”参考策略意味着不进行治疗。这两种参考策略的目的是帮助评估预测模型的效益和临床实用性。
在DCA的图像中,参考策略的效益始终为0。预测模型的效益曲线与参考策略的效益曲线进行比较,以确定预测模型在不同治疗决策阈值下的临床效益。如果预测模型的效益曲线在参考策略的效益曲线之上,则说明该预测模型在该治疗决策阈值下具有临床实用性。如果预测模型的效益曲线在参考策略的效益曲线之下,则说明该预测模型在该治疗决策阈值下没有临床实用性。
#构造一个全变量模型,及将其他剩余的变量都加入模型中,构建预测模型set.seed(123)full.model <- decision_curve(Cancer~Age + Female + Smokes + Marker1 + Marker2,data = dcaData,thresholds = seq(0, .4, by = .005),bootstraps = 10)plot_decision_curve(full.model,curve.names = "Full Model",cost.benefit.axis =FALSE,#col= c('red','blue'),confidence.intervals=FALSE,standardize = FALSE)
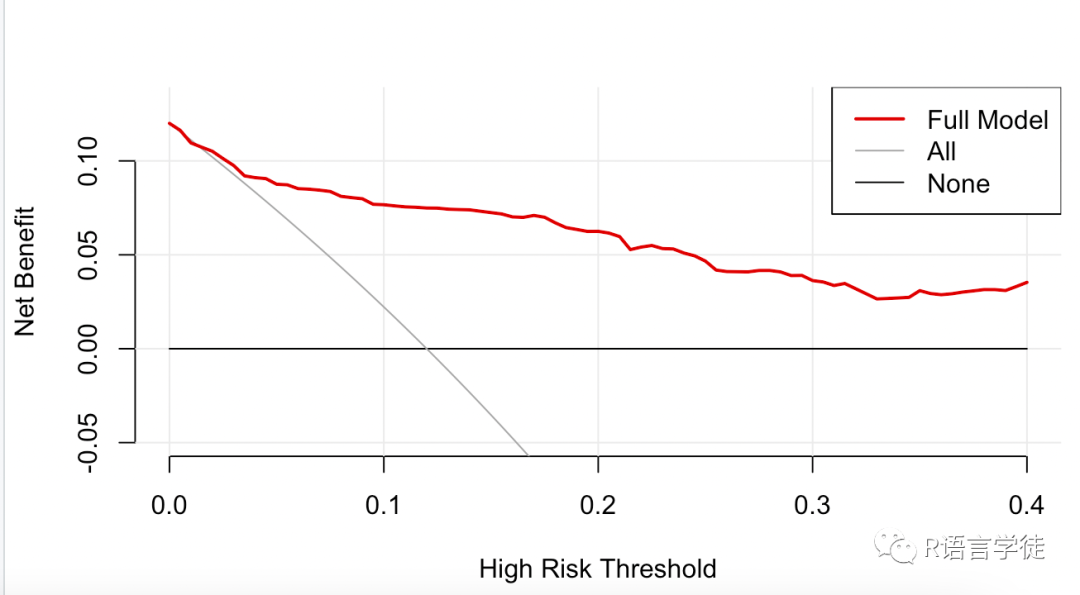
#对比模型plot_decision_curve(list(baseline.model, full.model), curve.names = c("Baseline model","Full model"), col = c("blue", "red"), lty = c(1, 2), lwd = c(3, 2, 2, 1), legend.position = "bottomright")
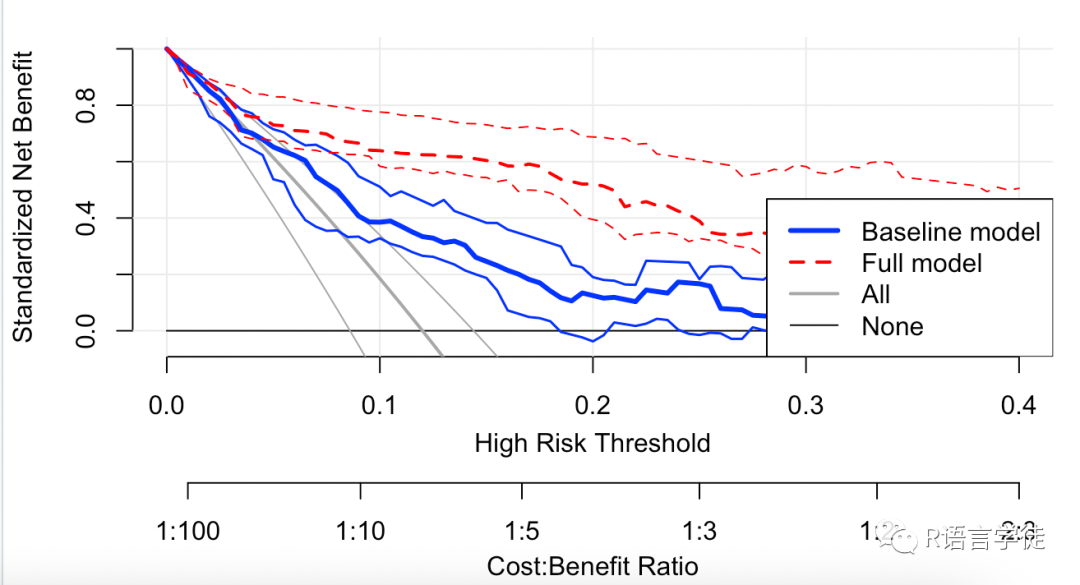
图中,cost-benefit轴是指横轴和纵轴的比例尺。在这个轴上,横轴表示治疗决策的阈值或概率阈值,纵轴表示决策收益,也称为净获利(net benefit)或净效益(net benefit)。
cost-benefit轴的比例尺是根据临床决策的成本和效益进行选择的。成本可以是治疗成本、测试成本、时间成本等,而效益可以是治愈率、生存率、疼痛减轻程度等。通过将治疗成本和效益考虑在内,可以确定在不同治疗决策阈值下的最优策略。
接下来再看看ggDCA工具包如何绘制DCA
data(LIRI)ddist <- datadist(LIRI) ###打包数据options(datadist = "ddist")
ggDCA 中dca可以完成单个或多个模型的DCA曲线绘制,模型对象包括四个:
-
coxph (Cox 比例风险回归模型,Fit Proportional Hazards Regression Model)
-
cph (Cox 比例风险回归模型,Cox Proportional Hazards Model and Extensions)
-
glm (广义线型模型,Fitting Generalized Linear Models)
-
lrm (逻辑回归模型,Logistic Regression Model)
同时还可以设置不同时期的预测效果,也可以在验证集里面进行验证。
#构建Logistic回归模型#根据不同情况,添加变量即为基因的个数,构建四个不同变量的Logistic 回归模型lrm1 <- lrm(status ~ ANLN, LIRI)lrm2 <- lrm(status ~ ANLN + CENPA, LIRI)lrm3 <- lrm(status ~ ANLN + CENPA + GPR182, LIRI)lrm4 <- lrm(status ~ ANLN + CENPA + GPR182 + BCO2, LIRI)#查看结果,包括阈值,真阳性,假阳性,净收益dca_lrm <- dca(lrm1, lrm2, lrm3, lrm4, model.names = c("ANLN", "ANLN+CENPA", "ANLN+CENPA+GPR182","ANLN+CENPA+GPR182+BCO2"))head(dca_lrm)

绘制,对比不同模型的DCA曲线
ggplot(dca_lrm, lwd = 0.5)
接下来看一下如果是构建COX回归的情况,步骤非常的相似,但是注意要导入一下survival包:
library(survival)#构建Cox回归模型cph1 <- cph(Surv(time, status) ~ ANLN, LIRI)cph2 <- cph(Surv(time, status) ~ ANLN + CENPA, LIRI)cph3 <- cph(Surv(time, status) ~ ANLN + CENPA + GPR182, LIRI)cph4 <- cph(Surv(time, status) ~ ANLN + CENPA + GPR182 + BCO2, LIRI)dca_cph <- dca(cph1, cph2, cph3, cph4, model.names = c("ANLN", "ANLN+CENPA", "ANLN+CENPA+GPR182","ANLN+CENPA+GPR182+BCO2"))head(dca_cph)

ggplot(dca_cph, lwd = 0.5)
这就是在R语言中绘制DCA决策曲线的两种方法啦!各位小伙伴学会了吗~欢迎留言和小师妹交流哦~
更多实用方便的小工具在云生信平台等着大家哦!
http://www.biocloudservice.com/home.html
★

