R语言包plyr的保姆级讲解,帮助你快速拆分应用汇总数据
生信人R语言学习必备
立刻拥有一个Rstudio账号
开启升级模式吧
(56线程,256G内存,个人存储1T)

R语言是一种功能强大的数据分析和统计建模工具,拥有众多优秀的数据处理包。在数据科学领域中,数据预处理是数据分析的重要步骤之一。plyr旨在提供一组简洁而强大的工具,帮助用户进行数据的分割、转换、汇总和应用。plyr的设计哲学是”分割-应用-合并”(split-apply-combine),也被称为”拆分-应用-汇总”。
首先,plyr的”拆分”过程是通过指定一个或多个变量来将数据分割成多个子集。用户可以根据自己的需求,将数据按照某个变量的值进行分组,也可以使用多个变量进行分组。其次,”应用”阶段是对每个子集应用用户自定义的函数。用户可以编写自己的函数,对每个子集进行操作,例如计算均值、中位数、标准差等统计量,或者进行自定义的数据转换。最后,”合并”阶段将所有子集的处理结果合并成一个最终的输出。plyr提供了灵活的合并方式,使用户可以根据需要将结果合并为数据框、列表或其他形式。
plyr包的强大之处在于它的高性能和可扩展性。通过内部使用C++代码和并行计算技术,plyr能够高效地处理大规模数据集和复杂的操作任务。它还支持用户自定义的函数,使用户能够根据自己的需求进行灵活的数据处理。
要使用plyr包,可以在R中使用以下命令进行安装和加载:
install.packages("plyr") #安装plyr语言包library(plyr) #加载语言包示例:加载plyr语言包library(plyr)# 使用mtcars数据集data(mtcars)# 添加一个随机列作为模拟的基因表达值set.seed(123)mtcars$gene_expression <- rnorm(nrow(mtcars))# 使用plyr包按照车辆类型(am字段)分组,并计算每个类型下基因表达的平均值result <- ddply(mtcars, "am", summarise, average_expression = mean(gene_expression))# 打印结果print(result)
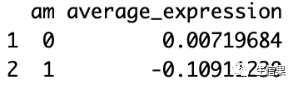
在上述示例中,我们首先安装并加载了plyr包。然后,我们使用data(mtcars)加载内置的mtcars数据集,该数据集包含有关不同汽车型号的信息。我们为模拟基因表达数据添加了一个名为“gene_expression”的随机列。
接下来,我们使用ddply()函数按照车辆类型(自动挡和手动挡)将数据分组。在ddply()函数中,第一个参数是数据集本身(mtcars),第二个参数是用于分组的变量名(“am”),然后我们使用summarise函数计算每个组中基因表达的平均值,并将其命名为“average_expression”。
最后,我们将结果打印出来,得到了按照车辆类型分组后每个组中基因表达的平均值。
这个示例展示了如何使用plyr包对生物学数据进行分组和计算。通过plyr的灵活性和简洁性,我们可以轻松地处理和分析更复杂的生物学数据集,从而获得对基因表达等关键生物学过程的深入理解。
示例:
> library(plyr)> library(ggplot2)> data <- data.frame(+ category = rep(c("A", "B", "C"), each = 4),+ value = rnorm(12)+ )> grouped_data <- ddply(data, "category", summarise, avg_value = mean(value))> ggplot(grouped_data, aes(x = category, y = avg_value)) ++ geom_bar(stat = "identity", fill = "steelblue") ++ labs(x = "Category", y = "Average Value", title = "Average Value by Category")
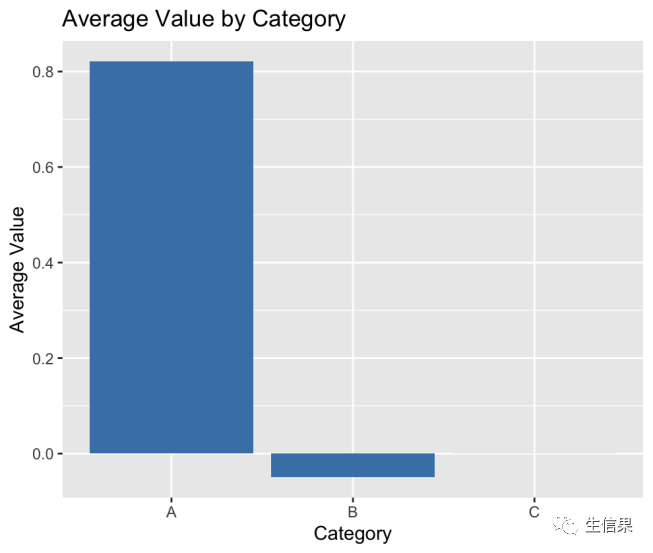
在上述示例中,我们首先安装并加载了plyr和ggplot2包。然后,我们创建了一个示例数据集data,其中包含一个名为“category”的分组变量和一个名为“value”的数值变量。
接下来,我们使用ddply()函数按照“category”变量对数据进行分组,并计算每个组的平均值。结果存储在grouped_data中。
最后,我们使用ggplot2包来绘制柱状图。在ggplot()函数中,我们指定了数据集grouped_data和绘图所需的映射关系。通过geom_bar()函数,我们将每个组的平均值作为柱状图的高度,并使用fill参数指定柱状图的填充颜色。labs()函数用于设置坐标轴标签和图表标题。
运行上述代码后,将生成一个基于数据分组的柱状图,其中每个组的平均值表示为柱状图的高度。这个示例展示了如何结合plyr包和ggplot2包进行数据处理和可视化,以更好地理解和呈现数据。
以上就是对R语言包plyr的简单介绍啦,plyr是一个功能强大的R语言包,提供了简洁而高效的数据处理工具。它的“拆分–应用–合并“策略使数据处理变得更加直观和可控。通过plyr,用户可以更轻松地进行数据转换、分析和建模,从而更好地理解和利用数据。无论是在学术研究、数据分析还是业务决策中,plyr都是一个不可或缺的工具,为用户提供了处理大规模数据集的强大能力。
小伙伴们,今天有没有学到新知识呢,想要继续了解R语言内容可以持续关注小果哦~~或者也可以关注我们的官网也会持续更新的哦~ http://www.biocloudservice.com/home.html
References:
1.https://www.google.com.hk/url?sa=i&url=https%3A%2F%2Fonunicornsandgenes.blog%2F2021%2F08%2F08%2Fusing-r-plyr-to-purrr%2F&psig=AOvVaw2yIfb1MxHi1Oh22qY5xMCU&ust=1689749833222000&source=images&cd=vfe&opi=89978449&ved=0CA4QjRxqFwoTCNjauubWl4ADFQAAAAAdAAAAABAI
2.https://www.google.com.hk/url?sa=i&url=https%3A%2F%2Fstackoverflow.com%2Fquestions%2F12603988%2Fwhat-is-the-ggplot2-plyr-way-to-calculate-statistical-tests-between-two-subgroup&psig=AOvVaw2yIfb1MxHi1Oh22qY5xMCU&ust=1689749833222000&source=images&cd=vfe&opi=89978449&ved=0CA4QjRxqFwoTCNjauubWl4ADFQAAAAAdAAAAABAQ
3.https://www.google.com.hk/url?sa=i&url=https%3A%2F%2Fbridgewater.wordpress.com%2F2011%2F06%2F10%2Fsimple-plyrggplot-example-of-cummulative-distribution-plots%2F&psig=AOvVaw2yIfb1MxHi1Oh22qY5xMCU&ust=1689749833222000&source=images&cd=vfe&opi=89978449&ved=0CA4QjRxqFwoTCNjauubWl4ADFQAAAAAdAAAAABAY
点击“阅读原文”立刻拥有
↓↓↓