干货!高分生信sci常用机器学习算法推荐——SVM
生信人R语言学习必备
立刻拥有一个Rstudio账号
开启升级模式吧
(56线程,256G内存,个人存储1T)

小果如期而至,又是想大家的一天呢。
什么是SVM?
小果今天带大家学习的技术点是一个经典的机器学习算法——支持向量机(SVM),这是一种常见的判别方法。在机器学习领域,是一个有监督的学习模型,通常用来进行模式识别、分类以及回归分析。那么这种算法能不能用到生信方向呢?
经过小果阅读多篇高分生信文章后发现,很多文章都用到了这个方法,说明这个方法不简单!接下来就和小果一起通过一个案例来学习一下吧!
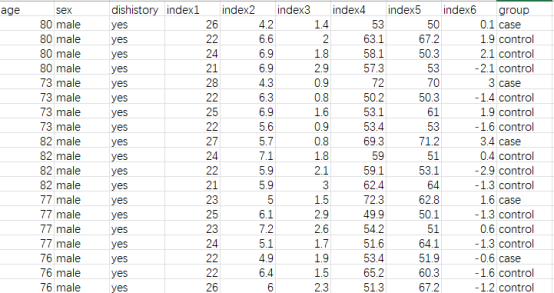
小果采用的数据是一个临床数据,其中每行为一个病人样本,每列为样本的特征,group为样本的分组。
数据样例展示
所需R包下载安装
#安装e1071包if(!suppressWarnings(require(e1071))){install.packages('e1071')require(e1071)}install.packages(“pROC”)R包调用library(e1071)library("pROC")
数据读取和数据集划分
#读取数据read.table("tree.csv",header=TRUE,sep=",")->mydata#对数据进行分组mydata$group<-factor(mydata$group)#划分测试集和测试集,260个样例作为训练集,其余作为测试集sub<-sample(1:392,260)train<-mydata[sub,]test<-mydata[-sub,]
模型搭建
#构建SVM模型svm_model = svm(group~.,data=train,knernel = "radial")#查看模型信息summary(svm_model)#对测试集数据进行预测svm_pred=predict(svm_model,test,decision.values = TRUE)test$svm_pred = svm_pred#输出混淆矩阵table(test$group,test$svm_pred)
结果可视化
#绘制ROC曲线ran_roc <- roc(test$group,as.numeric(svm_pred))pdf(file = "roc.pdf",width=12,height=9)roc<-plot(ran_roc, print.auc=TRUE, auc.polygon=TRUE, grid=c(0.1, 0.2),grid.col=c("green", "red"), max.auc.polygon=TRUE,auc.polygon.col="skyblue", print.thres=TRUE,main='SVM模型ROC曲线')dev.off()#绘制分类情况散点图attr(svm_pred,"decision.values")[1:9,]pdf(file = "point.pdf",width=12,height=9)plot(cmdscale(dist(test[,-10])), col = as.integer(test[,10]), pch=c("o","+")[1:132 %in% svm_model$index+1])dev.off()
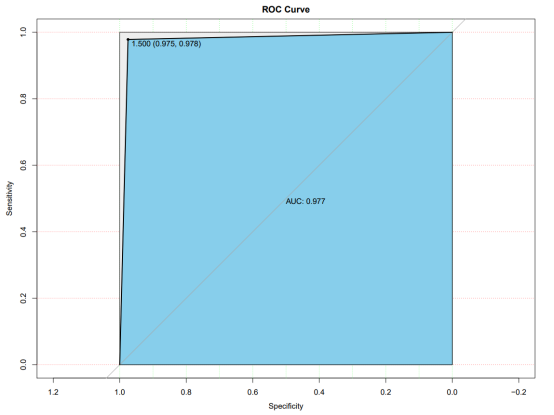
ROC曲线图
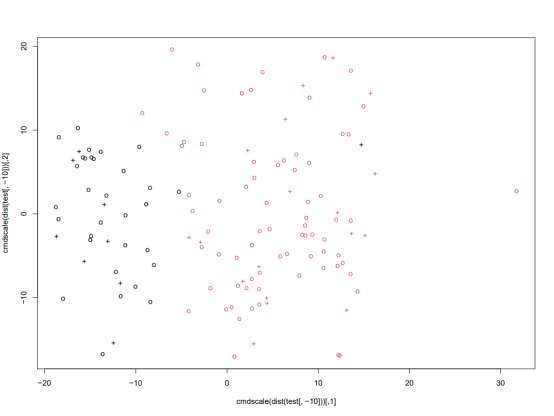
分类情况散点图
实验结果会得到ROC曲线图和分类情况散点图,其中ROC曲线绘制的图形面积表示了模型在测试集上的预测准确率,可以看到结果其预测准确率AUC=0.977,分类散点图表示了预测结果的分类情况,不同颜色代表不同分组,圆点代表结果预测准确,加号代表预测错误。
学习结束!小伙伴们有没有感觉茅塞顿开?相信大家以及蠢蠢欲动了吧,快自己动手试验一下吧!(小果新开发的零代码云生信分析工具平台包含超多零代码小工具,上传数据一键出图,感兴趣的小伙伴欢迎来参观哟,网址:http://www.biocloudservice.com/home.html)

微信号 | 18502195490
知乎 | 生信果
点击“阅读原文”立刻拥有
↓↓↓