十分钟学会R语言中的数据管理
点击蓝字,关注我们
数据的处理以及管理是数据分析过程中的一个重要的环节,今天就来学习一下关于R中数据的管理叭~
借鉴《R语言实践》第三版第三章基本数据管理https://livebook.manning.com/book/r-in-action-third-edition/chapter-3/v-9/1
示例展示
现在有一组数据,上司对5个不同的经理人满意程度的打分数据,(1非常不同意、2不同意、3即不同意也不赞成、4同意、5非常同意),表中还列出了一些日期、国家、性别和年龄等信息。
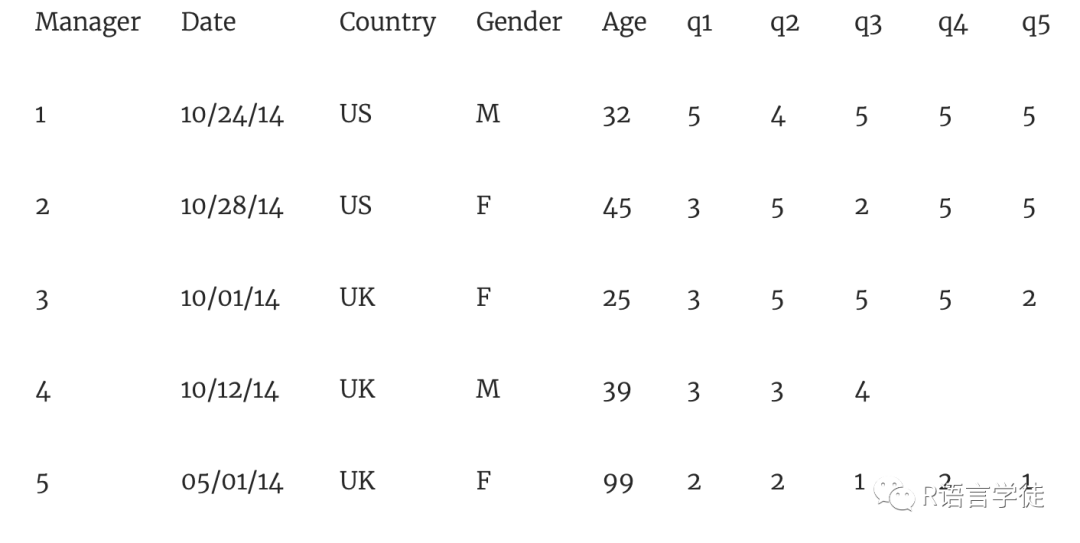
现在我们就用R进行数据的整理
manager <- c(1, 2, 3, 4, 5)date <- c("10/24/08", "10/28/08", "10/1/08", "10/12/08", "5/1/09")country <- c("US", "US", "UK", "UK", "UK")gender <- c("M", "F", "F", "M", "F")age <- c(32, 45, 25, 39, 99)q1 <- c(5, 3, 3, 3, 2)q2 <- c(4, 5, 5, 3, 2)q3 <- c(5, 2, 5, 4, 1)q4 <- c(5, 5, 5, NA, 2)q5 <- c(5, 5, 2, NA, 1)leadership <- data.frame(manager, date, country, gender, age,q1, q2, q3, q4, q5, stringsAsFactors=FALSE)
运算符
通过示例可以得到想要的数据集,但是还需要了解必要的运算符号,才能进行更好的管理数据集。运算符分为算数运算符和逻辑运算符:
数运算符

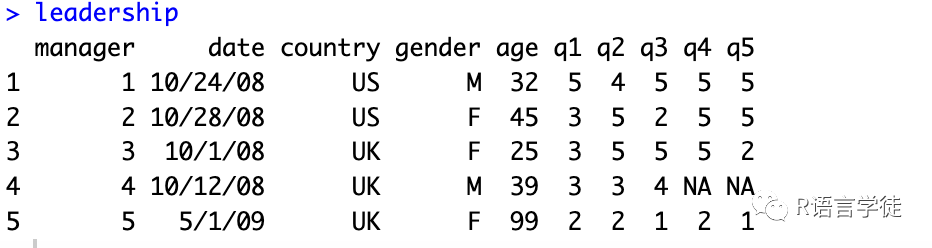
#第一种total_score <- q1 + q2 + q3 + q4 + q5mean_score <- (q1 + q2 + q3 + q4 + q5)/5#第二种total_score <- leadership$q1 + leadership$q2 + leadership$q3 +leadership$q4 + leadership$q5mean_score <- (leadership$q1 + leadership$q2 + leadership$q3 +leadership$q4 + leadership$q5)/5#第三种leadership$total_score <- leadership$q1 + leadership$q2 + leadership$q3 +leadership$q4 + leadership$q5leadership$mean_score <- (leadership$q1 + leadership$q2 + leadership$q3 +leadership$q4 + leadership$q5)/5#第四种leadership <- transform(leadership,total_score = q1 + q2 + q3 + q4 + q5,mean_score = (q1 + q2 + q3 + q4 + q5)/5)每一种都可以尝试一下,体会R数据管理的操作逻辑运算

#将年龄为99岁的值重编码为缺失值leadership$age[leadership$age == 99] <- NA#根据年龄进行赋值agecat列leadership$agecat[leadership$age > 75] <- "Elder"leadership$agecat[leadership$age >= 55 &leadership$age <= 75] <- "Middle Aged"leadership$agecat[leadership$age < 55] <- "Young"#还可以用within()函数写成leadership <- within(leadership,{agecat <- NAagecat[age > 75] <- "Elder"agecat[age >= 55 & age <= 75] <- "Middle Aged"agecat[age < 55] <- "Young" })

变量重命名的方法
names(leadership)[2] <- "testData"names(leadership)[6:10] <- c("item1", "item2", "item3", "item4", "item5")
缺失值
y <- c(1, 2, 3, NA)is.na(y)

分析中排除缺失值
x <- c(1, 2, NA, 3)y <- x[1] + x[2] + x[3] + x[4]z <- sum(x)
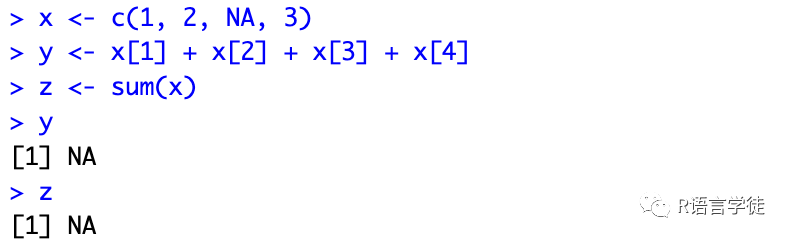
因为x有一个缺失值,因此y和z都是缺失值
#可以这样进行处理x <- c(1, 2, NA, 3)y <- sum(x, na.rm=TRUE)

用na.omit()删除不完整的观测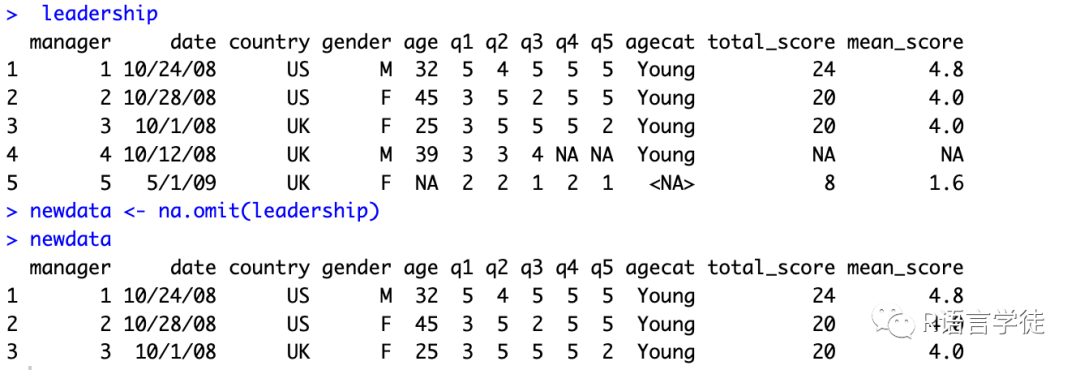
日期值:
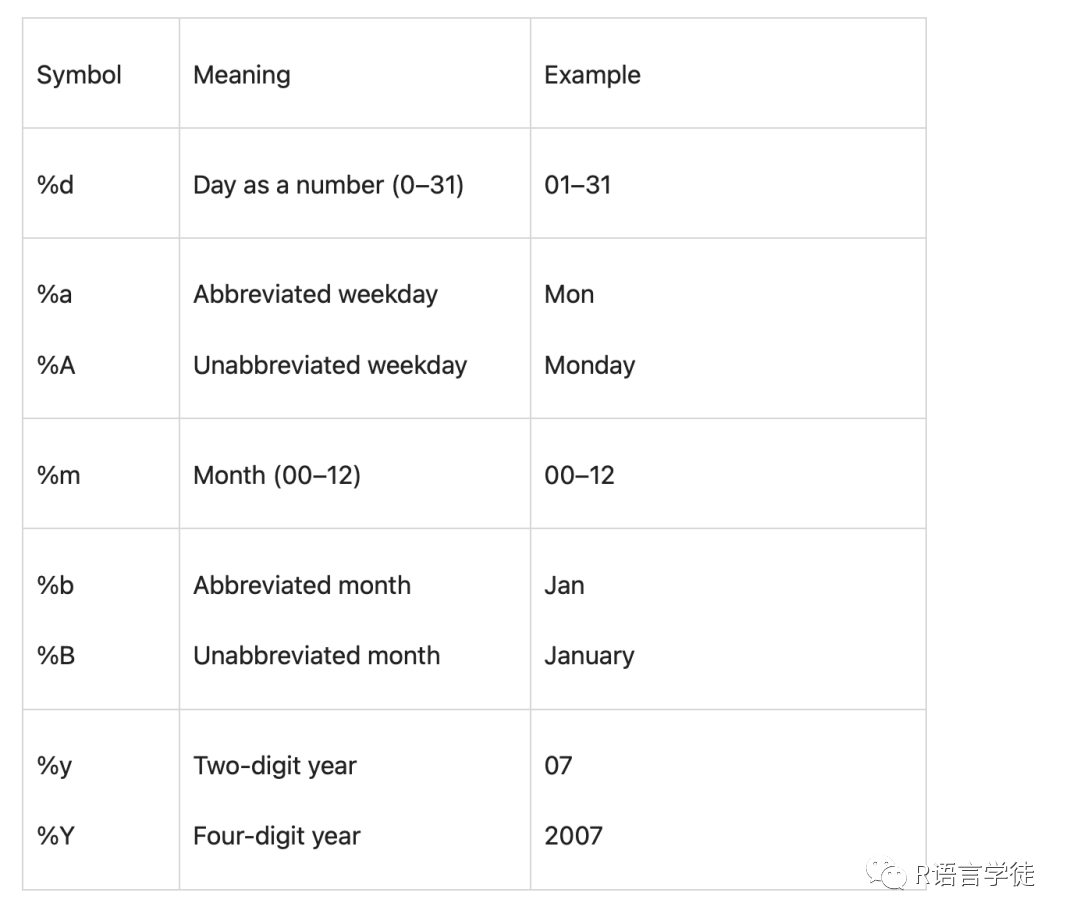
类型转化

> a <- c(1,2,3)> a[1] 1 2 3> is.numeric(a)[1] TRUE> is.vector(a)[1] TRUE> a <- as.character(a)> a[1] "1" "2" "3"> is.numeric(a)[1] FALSE> is.vector(a)[1] TRUE> is.character(a)[1] TRUE
数据排序
newdata <- leadership[order(leadership$age),]newdata <- leadership[order(leadership$gender, leadership$age),]newdata <-leadership[order(leadership$gender, -leadership$age),]#正的为升序,负的为降序数据集的合并#横向合并两个数据集,使用merge()函数,按照ID进行了合并total <- merge(dataframeA, dataframeB, by="ID")total <- cbind(A, B)#纵向合并total <- rbind(dataframeA, dataframeB)#添加行合并subset()函数取子集newdata <- subset(leadership, age >= 35 | age < 23,select=c(q1, q2, q3, q4))#age大于等于35或者小于23的,并且保留了q1到q4newdata <- subset(leadership, gender=="M" & age > 25,select=gender:q4#男性并且年龄大于25的,选择gender到q4的之间的列
dplyr包解决数据处理问题

通过以下操作理解dplyr处理数据集的作用:
建立数据集
manager <- c(1, 2, 3, 4, 5)date <- c("10/24/08", "10/28/08", "10/1/08", "10/12/08", "5/1/09")country <- c("US", "US", "UK", "UK", "UK")gender <- c("M", "F", "F", "M", "F")age <- c(32, 45, 25, 39, 99)q1 <- c(5, 3, 3, 3, 2)q2 <- c(4, 5, 5, 3, 2)q3 <- c(5, 2, 5, 4, 1)q4 <- c(5, 5, 5, NA, 2)q5 <- c(5, 5, 2, NA, 1)leadership <- data.frame(manager, date, country, gender, age,q1, q2, q3, q4, q5, stringsAsFactors=FALSE)library(dplyr)#修改列leadership <- mutate(leadership,total_score = q1 + q2 + q3 + q4 + q5,mean_score = total_score / 5)#重新编码leadership$gender <- recode(leadership$gender,"M" = "male", "F" = "female")#修改列名leadership <- rename(leadership, ID = "manager", sex = "gender")#根据列排序leadership <- arrange(leadership, sex, total_score)#筛选列leadership_ratings <- select(leadership, ID, mean_score)

#过滤sex为女性leadership_men_high <- filter(leadership,sex == "F" & total_score > 10)

dplyr可以解决很多我们数据分析中遇到的问题。
其实数据分析的数据集管理贯穿到整个分析的过程,如果你在数据分析中遇到困难可以寻求云工具哦http://www.biocloudservice.com/home.html
好了,这样我们你学会了R数据集的管理啦。小伙伴们如果有什么问题就和小师妹讨论吧。
★
