mlr3中的机器学习——进入生物信息学新时代(4)

点击蓝字 关注我们
哈喽,小师妹又和大家见面啦。在前面几节中,小师妹向大家介绍了在R语言机器学习领域占领半壁江山的mlr3包中的相关基础知识,其中包括task任务的创建,learner学习器的创建、修改等,不知道大家有没有认真学习呢,今天,小师妹将带着大家通过mlr3包做一次完整的机器学习分类练习,感受mlr3包的魅力。
在机器学习中,分类是一项基础且广泛应用的任务,涉及将输入数据分为预定义的类别或分类。分类算法的目标是基于带有标签的数据集,学习从输入特征到类别标签的映射关系,其中对于训练样本,正确的类别标签是已知的。学得的模型可以用于预测新的、未见过的数据点的类别标签。

以下是分类任务的简要概述:
1问题定义:
在分类中,你有一个数据集,其中每个数据点包含一组特征(也称为属性或输入变量)和一个相关的类别标签。任务是训练一个机器学习模型,可以基于数据点的特征预测其类别标签。
2类别类型:
类别可以是二元(两类)、多类(超过两类)甚至多标签(每个数据点可以同时属于多个类别)。
3训练数据:
训练数据包括带有标签的示例,其中每个示例都有输入特征和正确的类别标签。模型从这些数据中学习,以便进行准确的预测。
4特征提取:
预处理和特征工程是分类中关键的步骤。特征应该被选择或设计为向模型提供相关信息。
5模型选择:
分类有多种算法,包括逻辑回归、决策树、随机森林、支持向量机、k近邻和神经网络等。算法的选择取决于数据的性质、类别的数量以及特征与标签之间关系的复杂性。
6训练:
在训练过程中,模型调整其内部参数,以最小化在训练数据上的预测误差。这个过程涉及优化算法,迭代地更新模型的参数。
7评估:
训练好的模型使用指标(如准确率、精确率、召回率、F1分数和混淆矩阵)在一个独立的验证或测试数据集上进行评估,这是模型泛化能力的评价。
8预测:
一旦模型训练和评估完毕,就可以用于预测新的、未见过的数据点的类别标签。
9调整:
根据评估结果,你可能会微调模型的超参数或考虑替代算法以提高性能。
那么现在就让我们开始吧!
一.一个简单的分类任务
SUMMER
library(mlr3)set.seed(349)# 加载学习任务并进行数据划分tsk_penguins = tsk("penguins")splits = partition(tsk_penguins)# 创建基准学习器lrn_featureless = lrn("classif.featureless")# 创建学习器并进行超参数设置lrn_rpart = lrn("classif.rpart", cp = 0.2, maxdepth = 5)# 用acc进行模型评估measure = msr("classif.acc")# 训练lrn_featureless$train(tsk_penguins, splits$train)lrn_rpart$train(tsk_penguins, splits$train)# 基准模型评价lrn_featureless$predict(tsk_penguins, splits$test)$score(measure)# 人工模型评价lrn_rpart$predict(tsk_penguins, splits$test)$score(measure)
在上面的代码中,我们使用mlr3库加载数据、创建不同类型的分类器学习器,进行超参数设置,训练模型,并使用评估指标对模型进行评估。最后,展示了基准学习器和我们创建的学习器在测试集上的分类准确度评估结果。其中,”acc” 代表的是准确率(accuracy),这是一种常用的用来评估分类模型的指标。它衡量了正确预测的实例在总实例中的比例。


根据上面的输出,显然,人工学习器远远优于基准学习器,这说明,我们可以对选择的模型所得到的预测抱有信心。
二.分类任务绘制
SUMMER
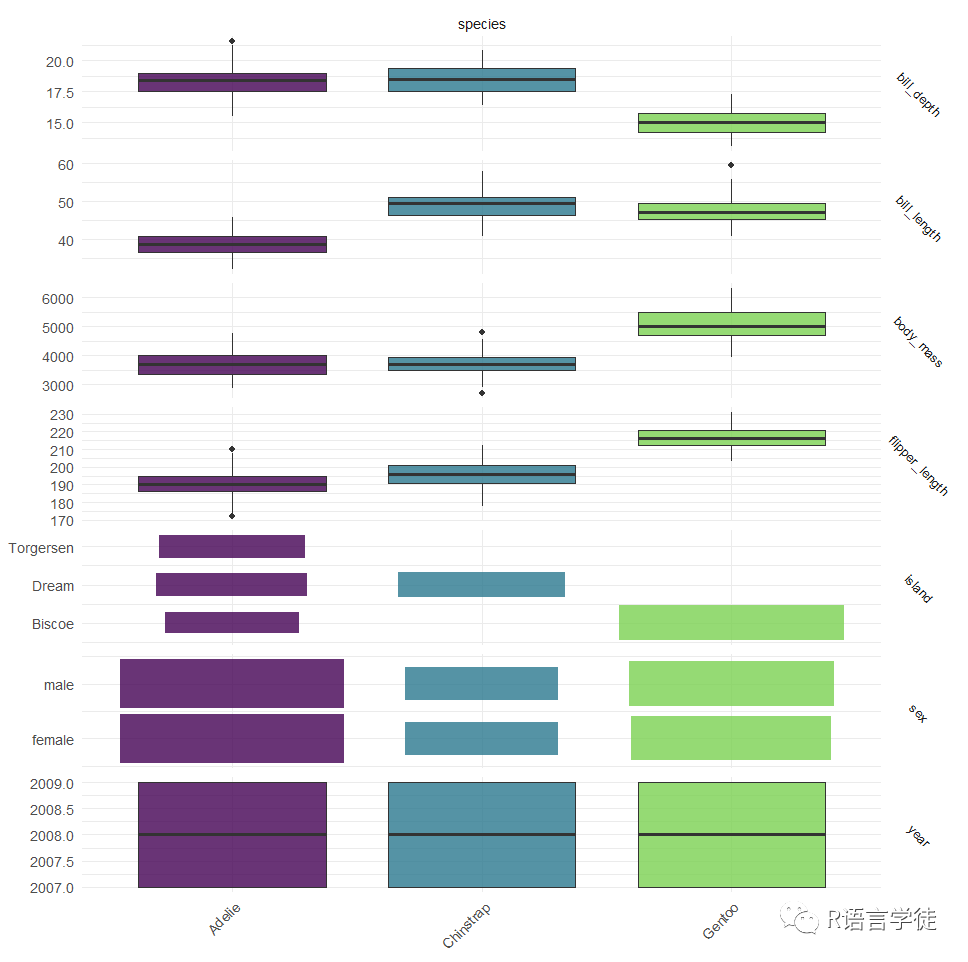
#绘制分类任务library(ggplot2)library(mlr3viz)autoplot(tsk("penguins"), type = "duo") +theme(strip.text.y = element_text(angle = -45, size = 8))
可以通过上述代码进行分类任务的绘制,用来观察不同类的特征变量的条件分布,可以用来判断哪些特征变量具有明显差异,适用于分类。
三.分类的软标签
SUMMER
分类的软标签(Soft Labels)是一种表示数据点在多个类别中的可能性分布的方式,而不是仅仅指定一个确定性的类别。软标签可以看作是每个类别的置信度或概率,用来表示一个数据点属于不同类别的可能性大小。
在传统的硬分类(Hard Classification)中,一个数据点被分配给一个唯一的类别,即选择具有最高概率的类别作为预测结果。然而,有时候数据点可能不太明确地属于一个类别,而是在多个类别之间存在一定的不确定性。
软标签允许分类模型输出关于数据点属于不同类别的概率分布,这可以提供更丰富的信息。例如,对于一张图片,传统分类可能会判定它属于”狗”这个类别,但使用软标签,模型可以表达它同时具有”狗”和”动物”这两个类别的可能性,以及其他可能的类别。在贝叶斯统计中,软标签对应于预测变量的后验概率。
通过在lrn中加入predict_type = “prob”,我们可以在predict中获取分类任务的软标签。
#获取分类的软标签lrn_rpart = lrn("classif.rpart", predict_type = "prob")lrn_rpart$train(tsk_penguins, splits$train)prediction = lrn_rpart$predict(tsk_penguins, splits$test)prediction
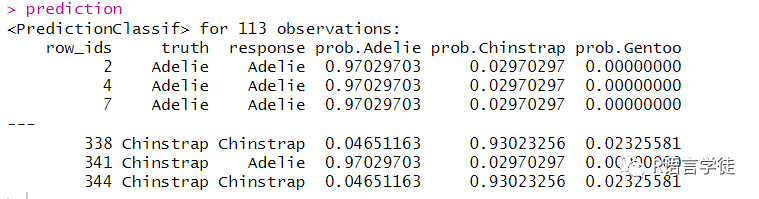
上述输出给出了分类任务的软标签,分别是最后三列,即变量从属不同类的后验概率。
四.混淆矩阵
SUMMER
混淆矩阵Confusion Matrix,是用于评估分类模型性能的工具。它对模型的预测结果与实际标签之间的差异进行了详细的分类并进行展示。混淆矩阵可以帮助我们了解模型在不同类别上的表现,从而更全面地评估分类器的效果。可以通过在predict对象后面加入$confusion来获取目标的混淆矩阵。
#混淆矩阵prediction$confusionautoplot(prediction)
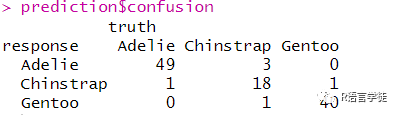
混淆矩阵中的行是预测类,列是真实类。所有非对角线条目都是错误分类的观测值,并且所有对角线条目都已正确分类。在这种情况下,分类器对所有企鹅进行了很好的分类,但我们本可以发现它只对Adelie物种进行了很好的分类,但经常将Chinstrap和Gentoo混为一谈。可以使用autoplot进行可视化预测的类标签。
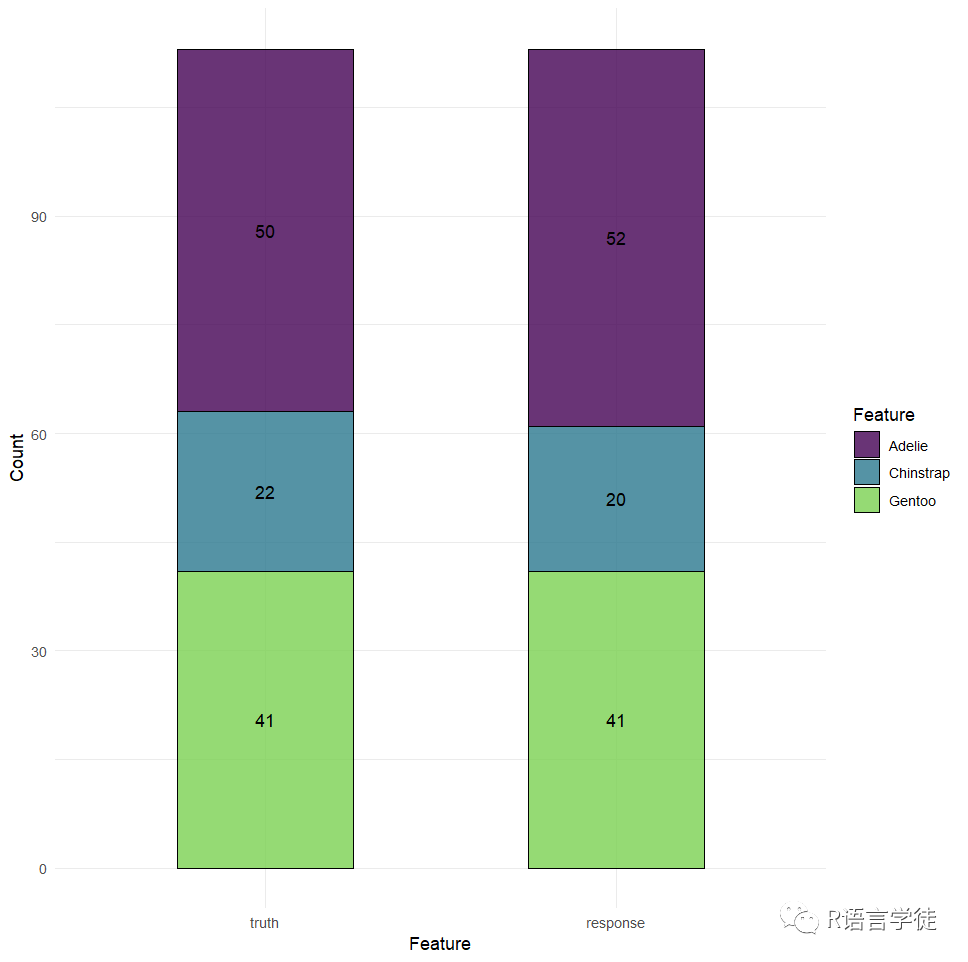
在二元分类的情况下,左上角的条目对应于真阳性,右上角对应于假阳性,左下角对应于假阴性,右下角对应于真阴性。
#一个二元分类的例子tsk_sonar = tsk("sonar")splits = partition(tsk_sonar)lrn_rpart$train(tsk_sonar, splits$train)$predict(tsk_sonar, splits$test)$confusion

五.阈值
SUMMER
阈值是分类任务和回归任务区分的关键,默认预测类型是预测概率最高的类。在一个二元分类中,这意味着如果预测类大于 50%,则将选择正类,否则将选择负类,这个 50% 的值称为阈值。有时,如果存在类不平衡(当一个类在数据集中代表性过高或不足时),或者如果存在与类相关的不同成本,或者只是如果偏好“过度”预测一个类,则更改此阈值可能很有用。例如,让我们以 700 个客户信用良好,300 个客户信用不佳为例。现在,我们可以轻松构建一个准确率约为“70%”的模型,只需始终预测客户将获得良好的信用:
#阈值的例子task_credit = tsk("german_credit")lrn_featureless = lrn("classif.rpart", predict_type = "prob")split = partition(task_credit)lrn_featureless$train(task_credit, split$train)prediction = lrn_featureless$predict(task_credit, split$test)prediction$score(msr("classif.acc"))autoplot(prediction)

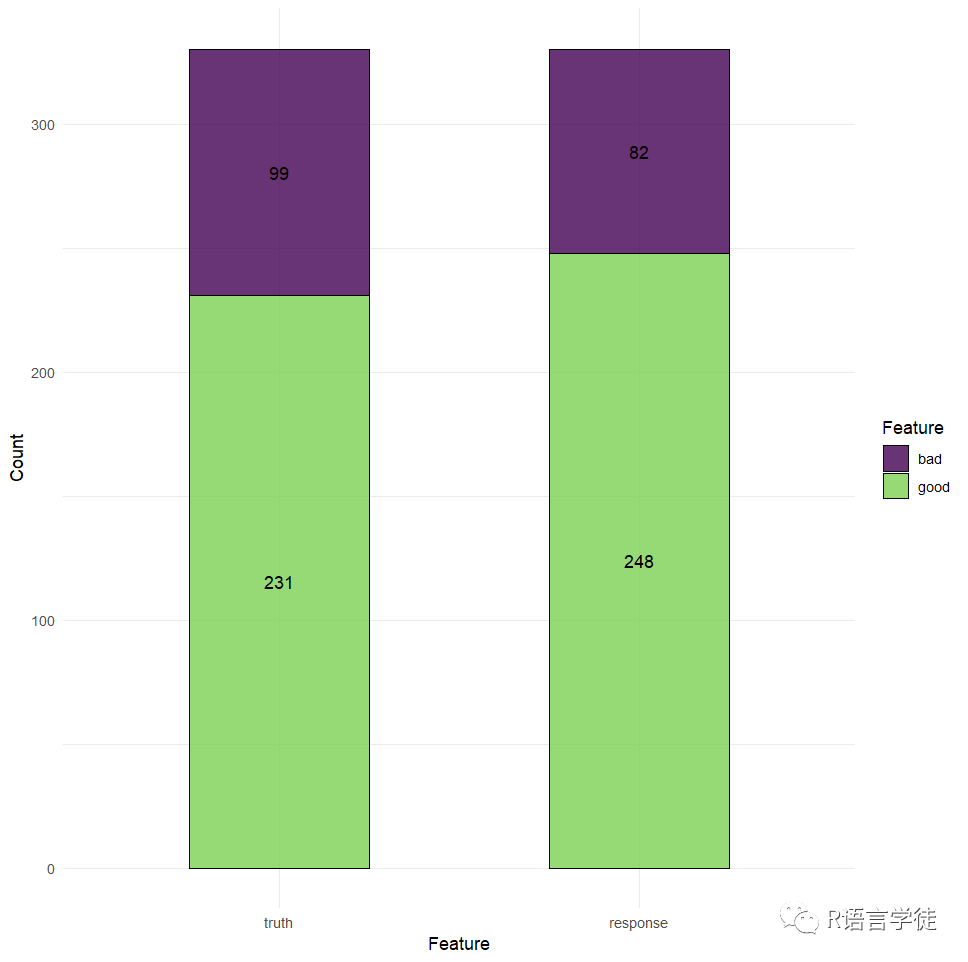
在没有设定阈值的情况下,虽然模型表面上看起来具有良好的性能,但实际上,它只是忽略了所有“坏”客户——这可能会在这个财务示例中以及医疗保健任务和其他误报成本高于漏报的环境中产生大问题,所以有时设置阈值也是至关重要的。(有时不仅仅需要精准率acc高,也需要召回率高,而往往两者是矛盾的,需要两者达到平衡)
我们设定阈值为0.8,即如果 P(好)< 80%,我们可以预测为信用不良。
#阈值设定lrn_rpart = lrn("classif.rpart", predict_type = "prob")lrn_rpart$train(task_credit, split$train)prediction = lrn_rpart$predict(task_credit, split$test)prediction$set_threshold(0.8)prediction$score(msr("classif.acc"))prediction$confusionautoplot(prediction)
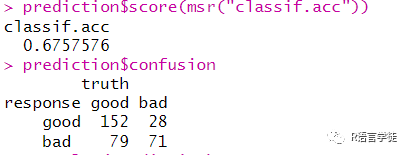
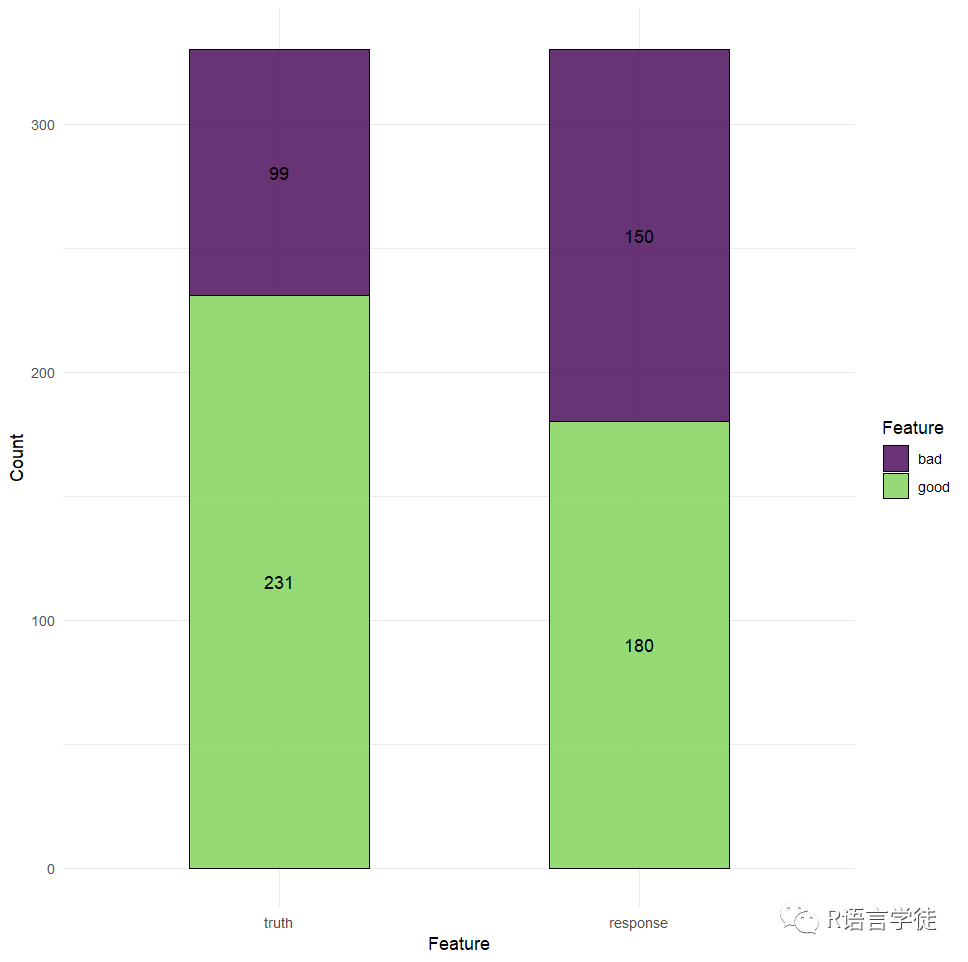
在这个例子中,我们可以看到,acc准确率降低了,但作为补偿,bad被预测为bad的情况远远增多,在这种情况下,虽然我们可能得到到相对更少的信用客户,但是我们会更不容易在不信用客户上犯错,这在有些场景下非常管用,有时能减少了可观的损失。
在多类分类中,阈值的工作原理是首先为每个类分配一个阈值,将每个类的预测概率除以这些阈值返回比率,然后选择比率最高的类。
#多类阈值probs = c(0.2, 0.4, 0.1, 0.3)thresholds = c(A = 0.5, B = 0.25, C = 0.25, D = 0.1)probs/thresholds
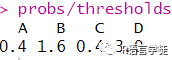
在上面的情况下,我们的观察结果将被预测在D类。
分类任务的学习就到这里结束啦,小伙伴们是否学会了呢,希望课下大家可以打开R语言一起练习哦。小师妹要和大家说再见咯,一定要自己练习一下哦,同时如果大家想要继续了解更多有关R语言内容可以持续关注小师妹哦~~或者也可以关注我们的官网也会持续更新的哦~ http://www.biocloudservice.com/home.html

