火过张元英摆胯?这套单细胞分类法实力强劲!港中文李煜团队9.5分:深度学习+自动注释+新型细胞检测,简单方法带来更强大的性能!

单细胞的文章咱见得多了,各种花样解锁的都有。今天小途也来玩把高端局,不再只是介绍一些文章套路复现了,咱们来看看大佬们如何从根本上优化单细胞数据分析的。
在单细胞研究中,传统上通过对细胞分组然后使用基因进行标记来进行。由于细胞图谱产量激增及其在速度、准确性和用户友好性方面的优势,自动注释工具开始占据主导地位。小途今天给大伙分享的新思路:用深度学习给细胞分类打标签的黑科技!对于热血沸腾,梦想在医药科研天空划出彩虹,还对深度学习跃跃欲试的朋友们,这就是咱们的新大陆呀。快来一起跟着小途的脚步,探秘一下深度学习在医学研究里的创新应用吧~
1,本文作者是第一个专注于新型稀有细胞发现的,并首次提出了分类方法scNovel;
2,本文使用深度学习方法结合百万规模测序分析数据集进行训练和测试,验证了该方法具有优越的性能和稳定性;
3,本文在不同新型稀有细胞类型和不同种群模式下,多角度验证了scNovel模型能够有效发现新型罕见细胞。
4,本文强调了模型可以快速对细胞类型进行分类,并揭示该方法具有较好的可扩展性。想要发表高分SCI的小伙伴们也可以借鉴一下本文的研究思路哦~ (ps:如何转变思路将算法应用到临床医学相关领域呢?让小途引领你探索生物医药研究的新领域,有兴趣的话快扫码交流吧!!)。


l题目:scNovel:一种基于深度学习的可扩展网络,用于单细胞转录组学中发现新颖稀有细胞
l杂志:Brief Bioinform
l影响因子:IF=9.5
l发表时间:2024年2月
研究背景
2009年Tang等人建立单细胞RNA测序(scRNA-seq),scRNA-seq能够分析单个细胞,为细胞异质性提供洞察,并已被广泛应用于生物体图谱生成、COVID分析、癌症研究、发育生物学研究等。在单细胞研究中,传统上通过对细胞点分组然后使用基因进行标记来进行。由于细胞图谱产量激增及其在速度、准确性和用户友好性方面的优势,自动注释工具开始占据主导地位。工具需要准确地查询细胞分类,还要识别参考数据集中不存在的新型细胞类型。然而,大多数以往的自动注释研究主要集中在通用细胞类型注释上,很少关注新型稀有细胞的发现。以往研究中并没有专注于新型稀有细胞检测,特征提取方法过于简单,导致生成的新型稀有细胞特征可能丢失信息。作者提出了一个集成的神经网络框架scNovel,并实现了良好的可扩展性和鲁棒性。
数据来源
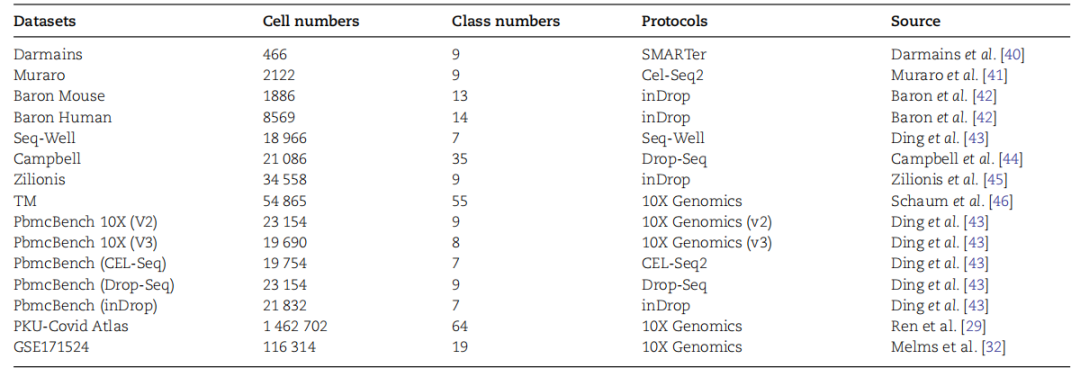
作者使用了共15个单细胞表达数据集,从小规模(约1k细胞)到大规模(约1.5m细胞)(表1)。作者结合了具有不同复杂度和排序规则的数据集,以显示本研究提出的模型的有效性和泛化性。
表1 不同规模的测序数据集
研究思路
作者提出了scNovel,其基本结构是一个基于深度神经网络的分类器。scNovel以单细胞基因表达作为输入,通过细胞类别的概率和阈值λ输出新细胞的检测结果。scNovel包含两个阶段,在训练阶段,作者采用交叉熵损失来训练模型,在分类器后输出细胞类型的概率预测。在查询阶段,如果概率小于阈值,则相应的单元格确定为新。一旦考虑的分数超过了阈值λ(通常定义为0.5),我们就确定它是新的。通过综合实验,scNovel的预测能力具有良好的应用前景。
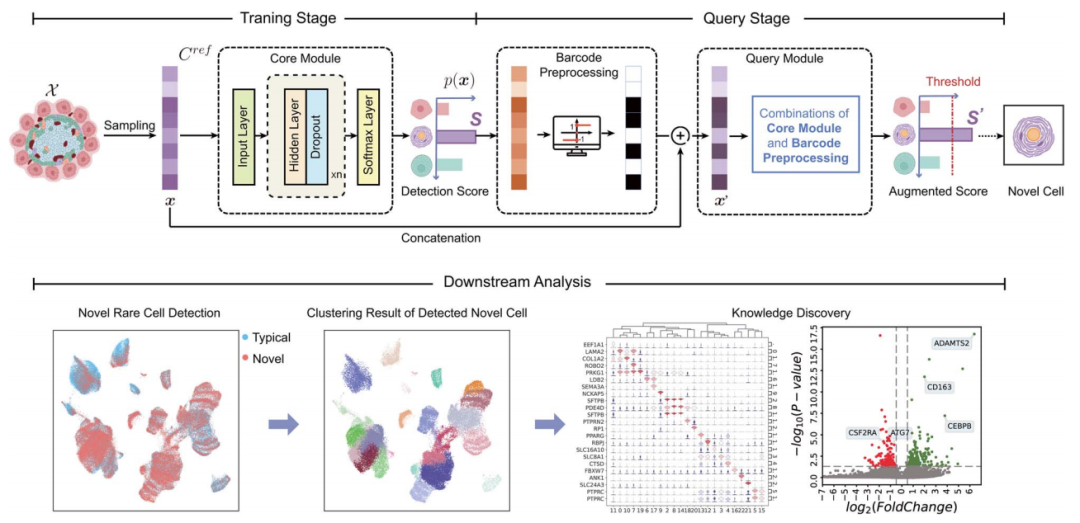
图1 scNovel模型框架
主要结果
1. 模型性能的综合评价
作者将scNovel与现有的细胞类型分类工具进行了性能比较。数据集选择涵盖了广泛使用的单细胞测序技术,包括10Xv2和10Xv3等。与以前的模型相比,作者提出的scNovel在不同数据集上的新型稀有细胞发现任务中,通过拥有最低的FPR95分数、最高的AUROC和最高的AUPR分数,显著提高了平均性能。当新型类别数(Cnovel)等于1时,scNovel的AUROC达到96.33%,大幅领先其他方法。所有结果一致表明scNovel在大多数情况下都显著优于其他方法,表明了采用的神经网络对于单细胞测序特征提取表现出了鲁棒性,特别适用于新型稀有细胞特征提取(图2)。在综合评价中,scNovel取得了最优的分类性能。
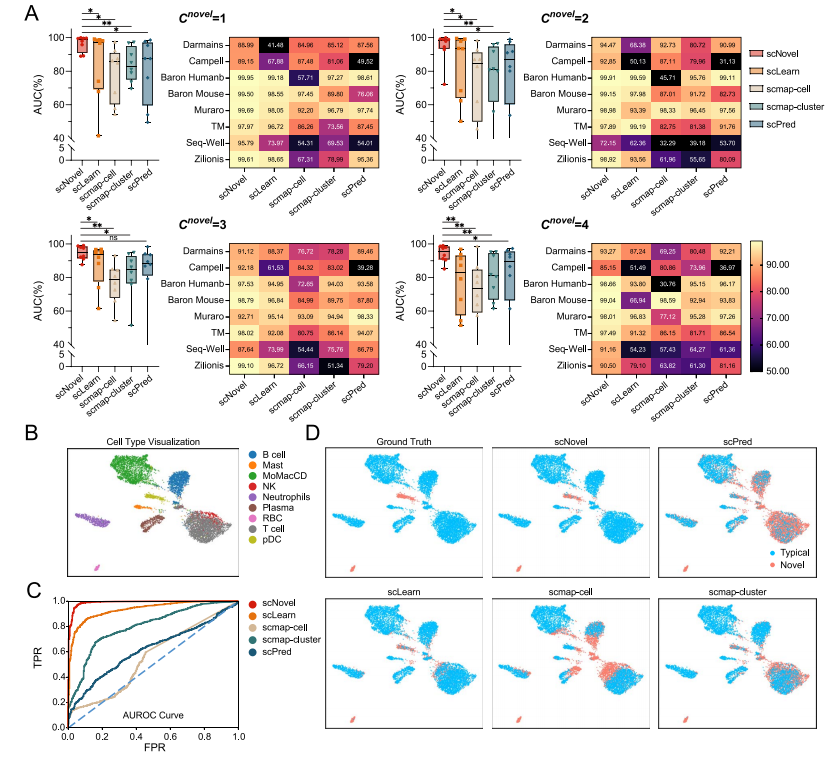
图2 性能测试和紫百合数据集上的可视化
2. 不同模式下不同新类别数量的一致性性能
作者通过不同的新型细胞类别数量Cnovel在不同模式下探讨了模型的性能。首先展示了模型在四种不同查询模式下的性能:利用最大预测概率作为分数的SMSP;只使用Tminus条形码预处理的SODIN;依次使用Tminus和Tplus条形码预处理的SSEQ;同时使用Tminus和Tplus条形码预处理的SSIM。通过详细的剖析研究,得出结论,SSIM应该是新型稀有细胞类型发现任务的最佳模式。接着,作者详细研究了在SSIM模式下不同Cnovel的scNovel性能。总体而言,scNovel在所有数据集上都有最佳的平均性能。scNovel的新型稀有细胞检测性能主要受细胞类型影响,并且对于不同的Cnovel具有鲁棒性。scNovel与Zilionis数据集中新型细胞发现任务的真实情况进行了UMAP可视化比较分析,结果表明作者提出的scNovel方法在不同Cnovel值下实现了显著一致的可视化性能(图3)。总之,scNovel在不同新型细胞类别数量和不同模式下的性能均具有更高的稳定性。
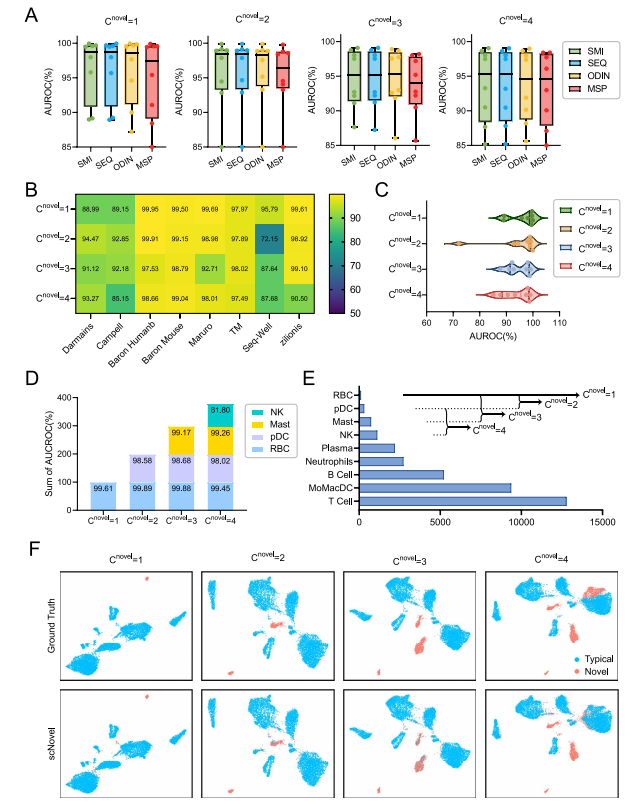
图3 不同数据集上的性能
3.稀有细胞类型识别的优势
在真实应用场景中,稀有细胞检测工具的训练和应用可以在具有不同数据集协议和平台上进行。作者收集了来自10Xv2、10Xv3、Drop-Seq、Cel-Seq、InDrop和Seq-Well的PBMCbench数据集,以评估scNovel跨平台检测新型稀有细胞的能力。与其他模型的对比结果表明了scNovel对跨平台注释任务中的潜在障碍具有鲁棒性。同时发现只有scNovel和scLearn成功检测到所有巨核细胞,而scmap-cell、scmap-cluster和scPred错过了部分巨核细胞。与scLearn相比,我们提出的scNovel有更少的假阳性预测,而scLearn错误地将CD16+单核细胞和细胞毒性T细胞判断为新型。此外,根据AUROC曲线,作者发现scNovel无论在任何FPR下都有比所有其他模型更好的TPR(图4)。scNovel在跨平台影响下保持了在新型稀有细胞类型发现任务中的卓越性能。
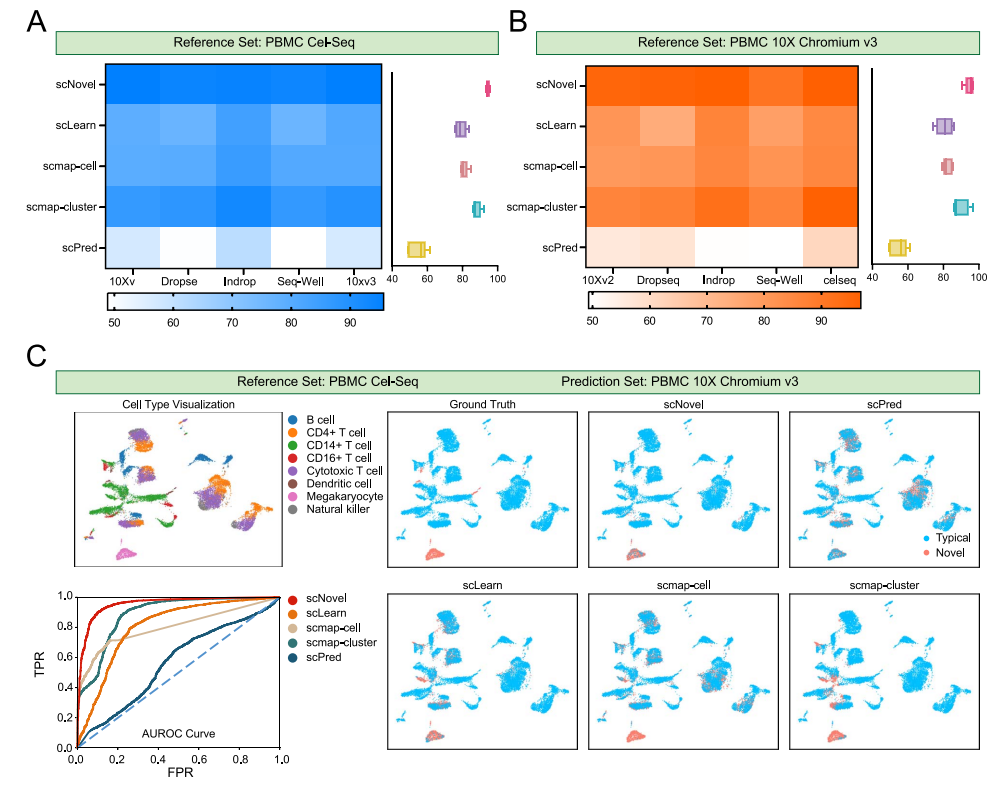
图4 在生成新型罕见数据的性能评估
4.提高scNovel的可扩展性
在真实世界的单细胞分析中,计算效率至关重要,被视为实现可扩展性的主要障碍。scNovel的运行时间在不同样本量的数据集中相对一致。对于超过30k细胞的数据集,scNovel相对于其他模型将运行时间减少了多达25%。分析显示,模型的运行时间主要受到两个因素的影响:计算和权重更新,以及数据准备阶段,这在不同数据集中保持不变。较小的数据集需要更频繁的数据准备,导致运行时间更长。因此,数据集大小直接影响模型的总运行时间。为了进一步验证模型性能在大型、不平衡数据集上的鲁棒性,作者将scNovel应用于百万规模的scRNA-seq数据集COVID-19免疫图谱(1,462,702个细胞)。结果表明scNovel能够准确识别在COVID-19案例中独有的10种新型稀有细胞类型(图5)。结果表明scNovel具有高度可扩展性,以及具有大规模实际应用的潜力。
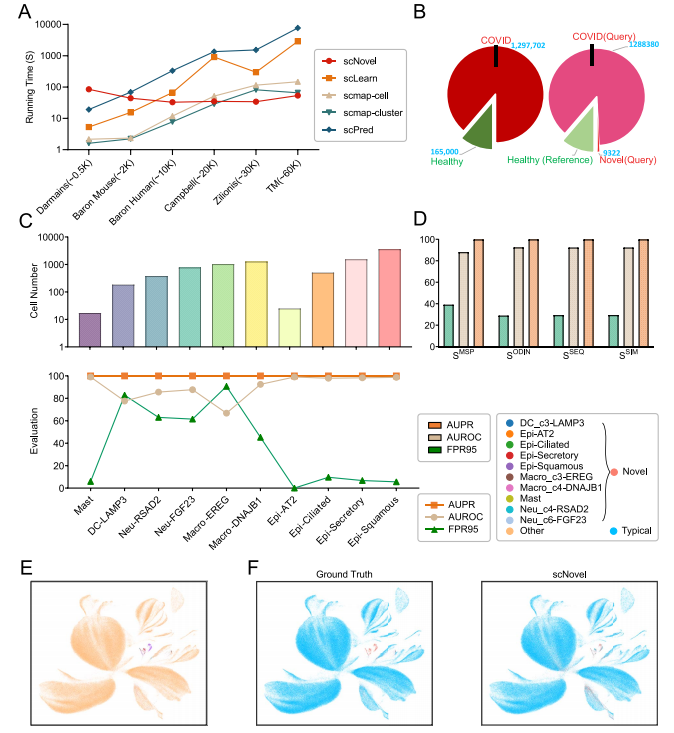
图5 时间复杂度与性能分析以及新细胞发现可视化
5.免疫细胞图谱中潜在新型亚型的发现和功能研究
研究表明,在生物医学领域,对特定细胞类型的遗传异质性进行细胞类型特异性分析非常重要。然而,新型细胞类型的检测过程既耗时又需要先验知识。作者提出的scNovel能够自动发现新型稀有细胞:(1)检测查询集的新型细胞;(2)使用Leiden聚类生成细胞群集;(3)利用新型细胞群集进行进一步分析。通过将scNovel应用于公开的COVID-19数据集,作者展示了细胞类型和患者注释的UMAP可视化,并成功地检测出AT1和AT2作为新型细胞。此外,通过展示新型细胞群集的最高基因表达及其关系,作者发现某些群集可能是巨噬细胞的亚型,并进一步分析了这些群集与COVID-19之间的关系。本研究不仅准确识别了独特的细胞类型,还通过GO分析探讨了不同COVID状态下巨噬细胞生物途径的变化,显示了scNovel作为加速未来大流行病或疾病诊断和应答的关键工具的潜力(图6)。scNovel能够自动发现并注释新型罕见细胞。
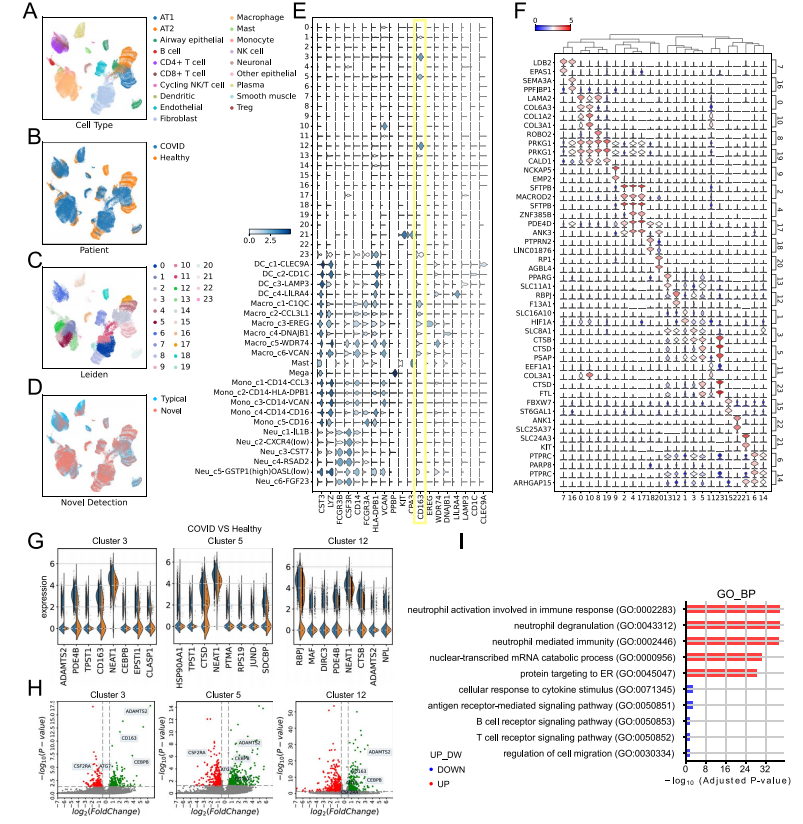
图6 UMAP可视化和聚类分析
文章小结
作者是第一个专注于新型稀有细胞发现的,并提出了第一个相应的自动检测模型scNovel。通过在不同规模、不同生成协议和不同Cnovel的多个scRNA-seq数据集上进行广泛实验,作者展示了有效的新型稀有细胞发现能力。同时还展示了scNovel在不同规模数据集上的快速运行速度,证明了其可扩展性。此外,作者在百万级别的数据集上评估了该模型,进一步展示了其可扩展性和新型稀有细胞发现能力。小途热情欢迎致力于临床医学和药物研究的同仁,一同利用深度学习与测序分析数据,打开高影响力学术论文的大门!这是激发创新思维、深化实验探索的绝佳时机。让我们勇敢面对科研新挑战,小途期盼与你携手前行~
小果还提供思路设计、定制生信分析、文献思路复现;有需要的小伙伴欢迎直接扫码咨询小果,竭诚为您的科研助力!
定制生信分析
服务器租赁
扫码咨询小果
往期回顾
|
01 |
|
02 |
|
03 |
|
04 |