¥6.80
购买后会显示你购买的服务器的账号和密码。并且发送服务器的账号和密码到你的邮箱作为备份。格式为xxxx:zzzz (以“:”分割,前边是账号,后边是密码),例如 xiaoyun:998899 那么你的服务器的账号和密码分别是xiaoyun和998899。
有了账号和密码后,不会登录服务器的参考链接:http://www.biocloudservice.com/wordpress/?p=292
有问题咨询客服,客服微信:18502195490
描述
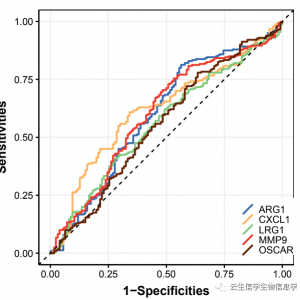
小编最近在阅读文献时,经常会看到研究两组样本对药物敏感性IC50值的差异,比如下面这个文章,作者通过构建了预后模型,将样本分成高低风险组,然后比较了两组样本对30种胰腺癌常用化疗药物的敏感性IC50值。

在以往的小编认知里,要研究药物敏感性差异必须要用药物处理后,观察两组的响应,因此小编一直苦苦感叹于没有足够的临床信息,也因此止步于此。直到看到了这篇文章,小编才发现利用基因表达矩阵,结合GDSC<www.cancerrxgene.org/>细胞系表达谱,通过构建岭回归模型就可以预测出样本对药物的IC50值,因此找到了该文章的方法部分,仔细研读后将代码进行了整理,这里我模拟的数据并不是以上文献的,而是其它癌症的,其中药物也是我随机挑选的,大家在运行的时候要根据自己的数据适当修改参数了。
附件包括了:(付费领取哦)
示例数据文件夹:里边是本次流程的输入文件
代码测试文件夹:里边是本次分析用到的代码
输出结果文件夹:里边是本次流程生成的示例图片
readme.txt文件 :是对输入文件的说明
以下是该流程分析出来的图片:
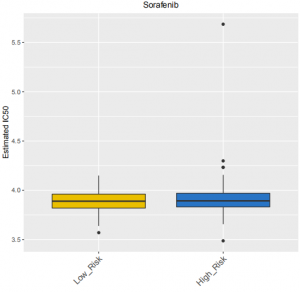
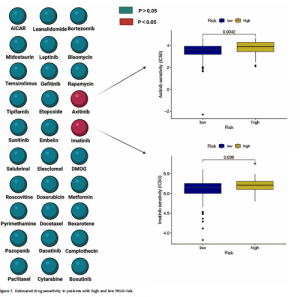
两组样本对某一种药物的敏感性IC50值分布,最上方标注了药物的名字,横轴表示的是组别名称。
此外,我们还输出了各个药物IC50值在两组样本中的显著性p.value值,并保存成output_pvalue.txt,如下图:
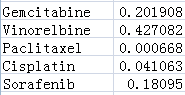
第一列为药物名称,第二列为显著性p.value值,一般认为p.value<0.05即表示该药物IC50值在两组样本间存在显著差异。