")
¥79.90
购买后会显示你购买的服务器的账号和密码。并且发送服务器的账号和密码到你的邮箱作为备份。格式为xxxx:zzzz (以“:”分割,前边是账号,后边是密码),例如 xiaoyun:998899 那么你的服务器的账号和密码分别是xiaoyun和998899。
有了账号和密码后,不会登录服务器的参考链接:http://www.biocloudservice.com/wordpress/?p=292
有问题咨询客服,客服微信:18502195490
描述
1、打开命令行界面,输入“Rscript run_LDA.R –h”查看软件详细的帮助文档,确定该程序所需的输入文件和关键参数的设置。
2、用户根据帮助文档中的参数说明内容,对参数进行设置。这里,必须输入参数有2个,分别是Abundance File,表示物种的丰度矩阵文件,以物种或OTU为行,样本为列,保存为csv文件;Meta File 表示各个样本的meta信息文件,第一列为样本名,后面每一列为样本的某一种分组或实验类型,也保存为csv文件。需要确保Abundance File中出现的样本名,在Meta File 中必须能够找到。–g,表示选取Meta矩阵中的某一列作为分组依据,进行LDA分析。其余参数为可选参数,在用户没有显式指定的情况下,将采用默认值运行。具体说明如下:–h,输出软件帮助文档;–v,输出软件版本号;–k,kruskal.threshold,kruskal 非参数检验的p值,只有小于此阈值的微生物会被保留下来;–w, wilcox.threshold, wilcox非参数检验的的p值,只有小于此阈值的微生物会被保留下来;–l, lda.threshold, lda score的回归系数阈值,绝对值大于此阈值的会被保留;–b,第二个分组变量的列名;–o,结果输出文件的前缀。参数符号的string,number提示该参数的数据类型。
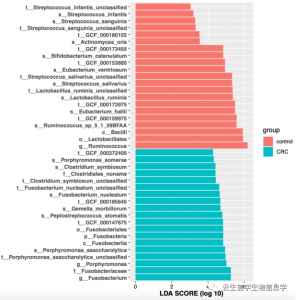
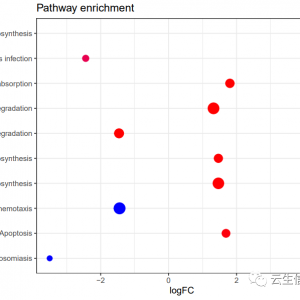
该图表示在用户指定的分组中显著差异的大于设定阈值的biomarker。LDA score分值越大,差异越大,表示在该组中丰度显著高于其他组。不同的颜色用于区分不同的分组。
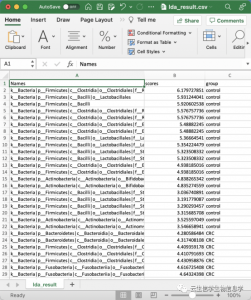
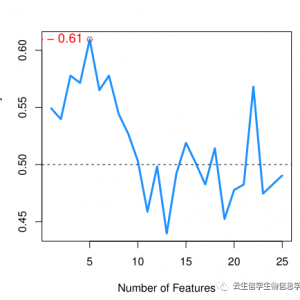
该表格表示各个差异物种的具体LDA分数值,共有三列,第一列是具体的物种或OUT名称,第二列是具体的LDA Score,是对原始LDA score去log10之后的数值, 第三列是该物种显著富集的分组。